Are You Getting The Best Version of Your LLM?
We investigate how language and culture are entangled in LLMs

This blog is a brief overview of our research paper: Language Models Entangle Language and Culture. It was accepted at LM4UC Workshop, AAAI 2026.
Read the full paper here: https://alphaxiv.org/abs/2601.15337
TL;DR:
Large Language Models (LLMs) provide answers of varying quality to generic subjective-type questions across languages.
The cultural context used by LLMs when generating responses depends on the language of the query.
The entanglement of language and culture in LLMs impacts their performance on downstream tasks.
Why Should You Care?
All of us use LLMs for the simplest of queries on a regular basis, ranging from tips on improving sleep quality to help with preparing for job interviews. While there has been a lot of research evaluating performance gap on math, coding or reasoning tasks across languages, there is an existing gap in evaluating LLMs on generic queries. Additionally, there is a lack of work investigating how language and culture are related in LLMs and how this relationship qualitatively affects the generated responses.
Question Generation
To develop the questions for this evaluation, we wanted to ground our questions by analyzing what users usually ask LLMs. We analyzed the WildChat Dataset which contains about ~4.8M queries users have asked ChatGPT by filtering based on query length (removing too short and too long queries), removing duplicate or highly similar queries and then clustering queries using the HDBSCAN algorithm to identify the major topics/areas and query types that users ask. We finally chose the following areas for evaluation and manually created a set of 20 questions:
Programming Advice
Research Advice
Trading/Investing
Learning
Business/Marketing
Job/Interview
Health/Medicine
The full list of questions generated can be found in the paper.
Evaluation
We use LLM-as-a-judge for evaluation with Cohere-Command-A as the judge model due to its high multilingual capabilities. We carry out two kinds of evaluations:
Answer Quality
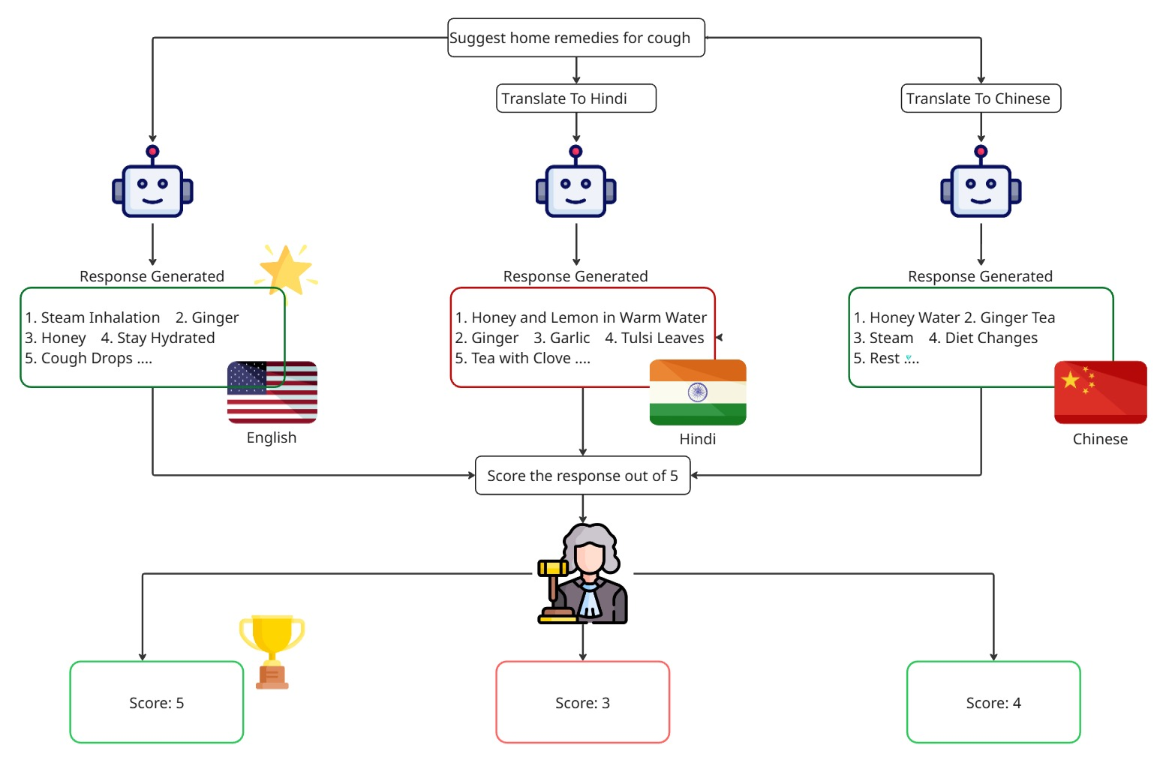
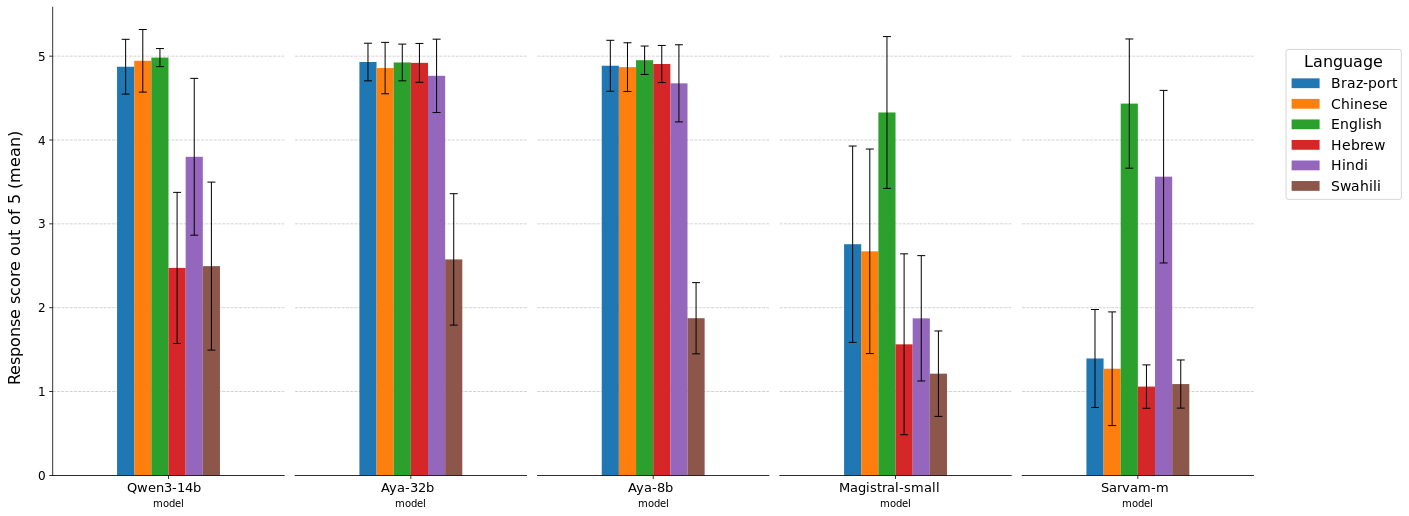
We first evaluate whether the quality of answers is different across languages. For this, we generate 10 responses per question in each of these 6 languages: English, Hindi, Chinese, Swahili, Hebrew and Brazilian Portuguese. In total, we generate 1200 responses per model. We pass the response in the native language to the judge model and ask it to evaluate the response out of 5 given the query and the rubrics. The results for this evaluation can be found in the earlier figure in the blog.
To ensure that low scores for responses generated in some languages are not due to language bias of the judge model, we translate a subset of responses in English to Hindi and a subset of responses in Hindi to English using Gemini-2.5-Flash. We evaluate the translated responses using the same LLM-as-a-judge setup and calculate the average scores.
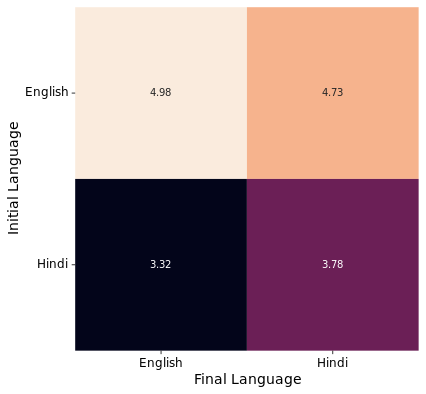
Results show that responses generated in Hindi and translated to English score lower on average than responses generated in Hindi and evaluated in the native language itself (lower row of the image). Also, the responses generated in English translated to Hindi retain their high scores compared to responses generated in Hindi (right column of the image). We note that translation to either languages leads to some reduction in scores as the translation is lossy, but the judge model does not show any language bias.
Response Context
In the second part of evaluation, we translate all responses to English using Gemini-2.5-Flash and ask the judge model to predict which cultural context the answer represents. We translate all responses to English to ensure that the judge model does not predict cultural context based on language. For each response, cultural context is classified as one of:
English (Western/Anglo-American)
Chinese
Indian
Jewish
African
Brazilian-Portuguese/Latin
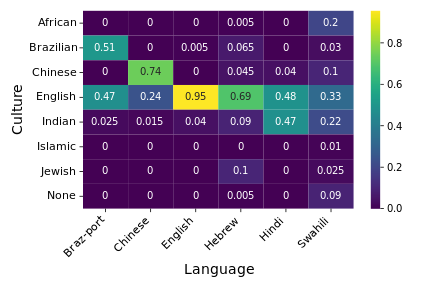
We find that even after translating all responses to English, the judge model is able to identify cultural context from the responses, with 95% of responses in English are classified as English (Western/Anglo-American), 47% of responses in Hindi are classified as Indian, 74% of responses in Chinese are classified as Chinese. This shows that responses generated contain cultural cues that were identifiable even after translation. This verifies that language of the query leads to responses with different cultural context, hence showcasing that language and culture are entangled in LLMs.
To further verify the entangled nature of language and culture in LLMs, we translated a subset of CulturalBench with 789 questions covering 29 countries to Hindi, Chinese, Swahili, Hebrew and Brazilian Portuguese using Gemini-2.5-Flash. We evaluate Qwen3-14b on this subset across languages with temperature set to 0.
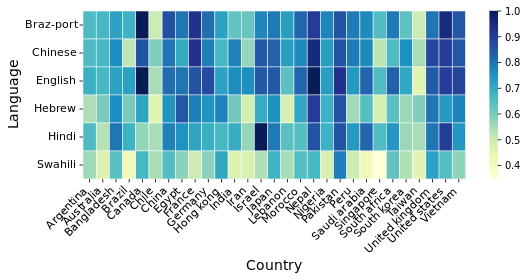
We find that performance for the questions related to each country varies by language. We believe this is due to the language using different cultural context based on the language of the query, which affects the performance when answering questions.
We conducted further ablations and analysis to verify the validity of our results and to show that language and culture are entangled in LLMs. To know about other experiments, details of our LLM-as-a-judge setup and prompts used for evaluation, read the full paper: https://www.alphaxiv.org/abs/2601.15337.
Shourya Jain & Paras Chopra — Lossfunk Research
📧 shourya.jain@lossfunk.com | paras@lossfunk.com
Very interesting! Lingo-cultural differences are definitely quite a significant issue with current LLMs.