Can an AI actually be your research mentor?
An AI research mentor that moves undergrads from "I have no idea" to a paper draft, with stage-aware guidance, tools, and measurable gains.

This is a summary of our preprint: METIS: Mentoring Engine for Thoughtful Inquiry & Solutions
Full paper: https://arxiv.org/abs/2601.13075
AlphaXiv: https://www.alphaxiv.org/abs/2601.13075
Code: https://github.com/lossfunk/ai-research-mentor
TL;DR
We built METIS, a stage-aware research mentor that adapts guidance to where a student is in the research process (A: pre-idea → F: final).
Across 90 single‑turn prompts, LLM judges preferred METIS 71% vs Claude Sonnet 4.5 and 54% vs GPT‑5.
Student‑persona rubrics show higher clarity, actionability, and constraint‑fit, especially in later stages that use document grounding.
Multi‑turn tutoring improves slightly over GPT‑5 on final quality, with gains concentrated in document‑grounded stages.
The biggest lift shows up when students already have a draft and need precise, grounded feedback rather than generic advice.
The problem we cared about
Most students don’t have a research mentor. Even when they have access to strong models, the guidance is generic and often skips steps. A student might ask, “How do I start research in AI?” and get a polished answer that still doesn’t move them forward.
In practice, the real pain shows up later too. Students get a half‑formed idea, run into a feasibility wall, or collect notes without knowing how to turn them into a method section. The gap isn’t just knowledge; it’s sequencing. Good mentors know what to ask next and what to ignore for now.
We wanted something more specific: an AI mentor that keeps track of where the student is in the research journey and nudges them forward with the right tools and checks.
That’s METIS.
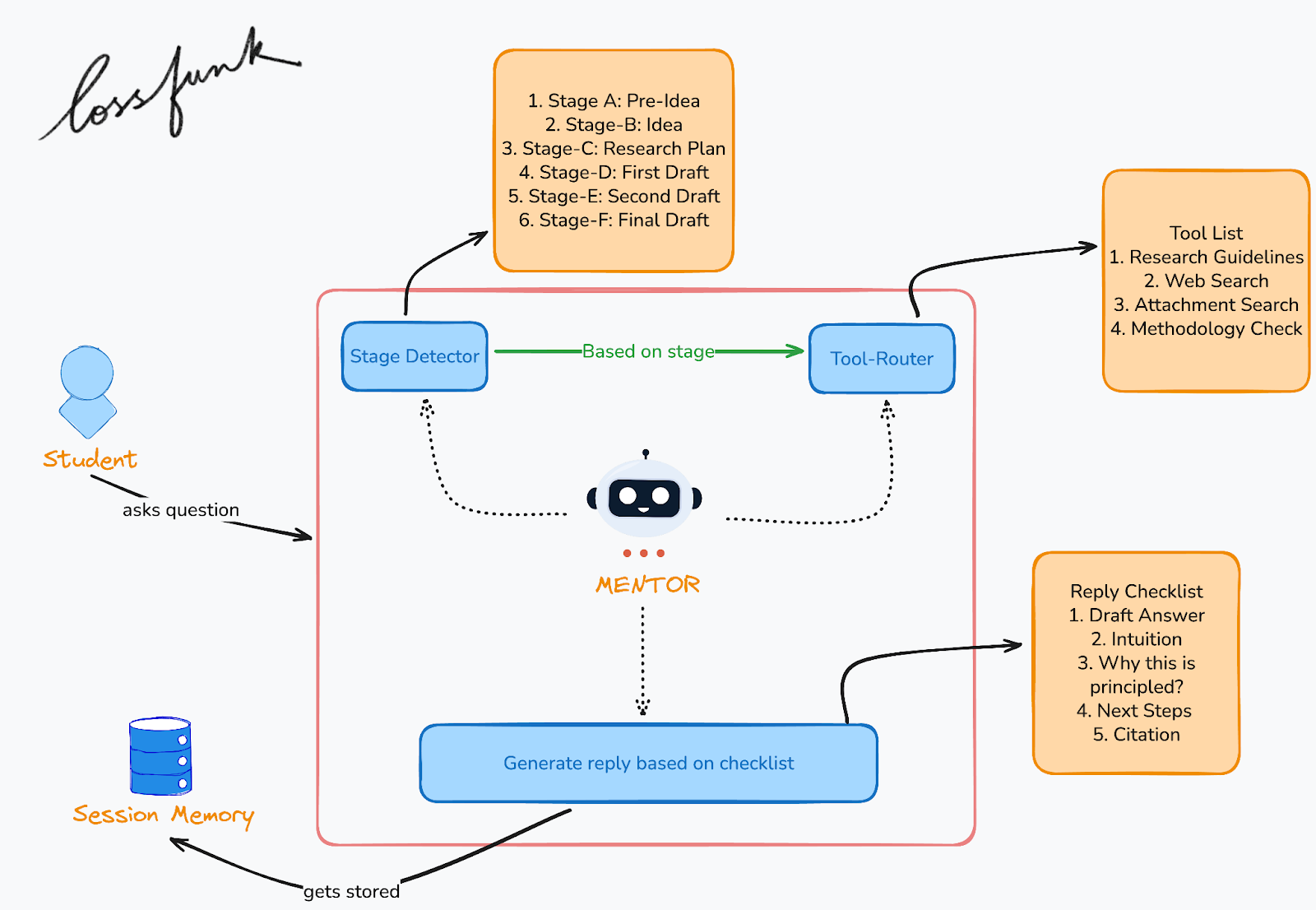
What METIS actually does
METIS is stage‑aware. It classifies the student’s current stage and routes tools accordingly:
A (Pre‑Idea): orientation, constraints, research areas
B (Idea): feasibility, novelty checks, risks
C (Plan): timelines, baselines, ablations
D (First draft): methodology checks, missing evidence
E (Second draft): limitations, discussion, reviewer‑style critique
F (Final): submission checklist, artifact planning
The response always includes two explicit blocks:
Intuition
Why this is principled
Those aren’t fluff. They force the mentor to surface its reasoning and justify advice against grounded evidence or known research heuristics. It also helps students see the logic behind the suggestion, which makes it easier to act on.
The tools matter, but the ordering matters more. A student in Stage B needs a novelty check; a student in Stage E needs a reviewer‑style critique and a tighter limitations section. METIS is built to respect that.
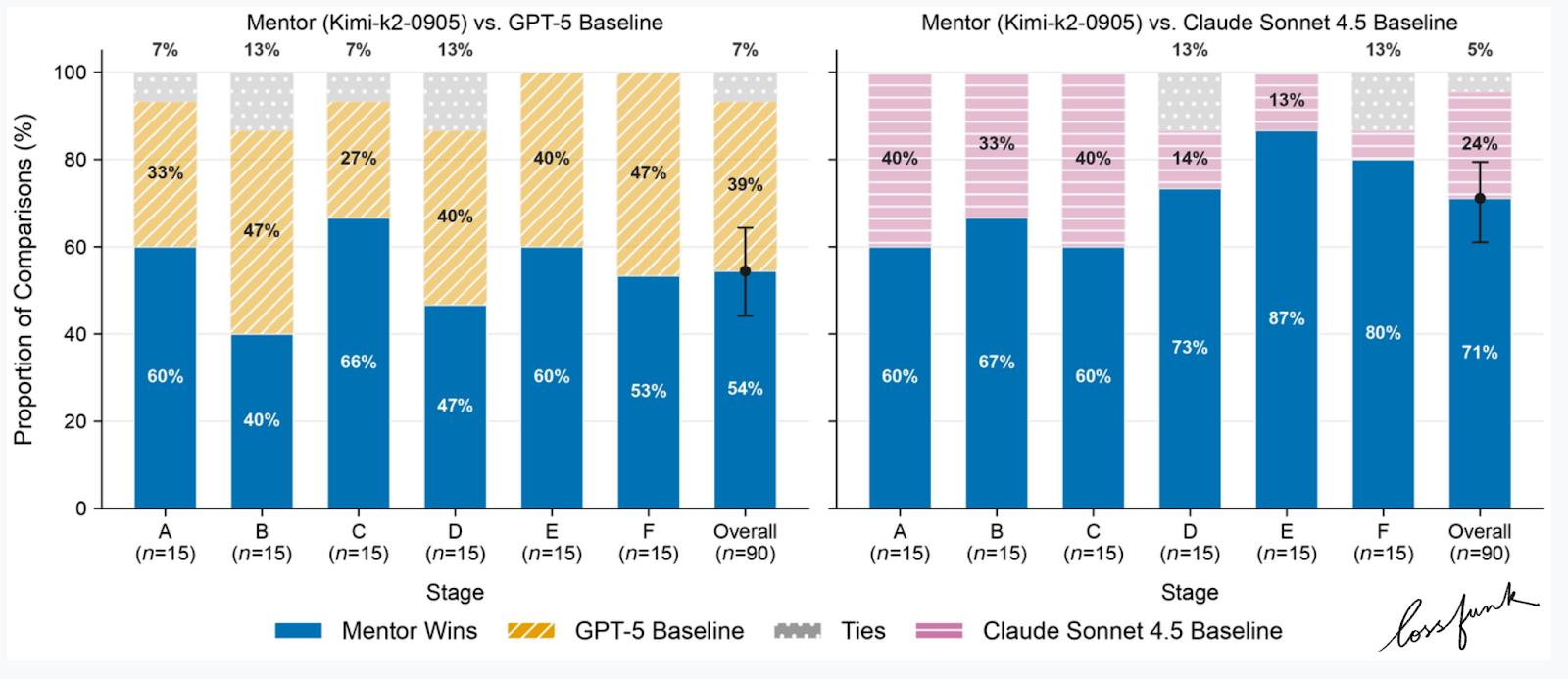
Evaluation setup
We tested METIS against GPT‑5 and Claude Sonnet 4.5. All systems had web and document search; METIS had an extra Research Guidelines tool.
Benchmark:
90 single‑turn prompts (15 per stage A–F)
5 multi‑turn tutoring scenarios per system
Judges: Gemini 2.5 Pro, DeepSeek v3.2‑exp, Grok‑4‑fast
Metrics included LLM‑judge preferences and student‑persona rubrics (clarity, actionability, constraint‑fit). We also tracked whether the responses stayed inside each student’s constraints (time, compute, course level), since that’s where generic advice tends to fall apart.
Results that matter
Single‑turn (LLM‑judge):
METIS beats Claude Sonnet 4.5 in 71% of prompts
METIS beats GPT‑5 in 54% of prompts
Gains are strongest in later stages (D–F) where document grounding matters
One pattern that kept showing up: METIS does best when the prompt includes real material. If the student shares a draft, an outline, or a methods blurb, METIS can reference it directly and tighten the advice. The baselines tend to reply with broadly correct but less actionable feedback.
Student rubrics:
Higher clarity, actionability, constraint‑fit across stages
Improvements are consistent in later stages
On clarity, the wins aren’t subtle. Students get fewer “do more literature review”‑style answers and more specific next steps, like what to measure, what to fix in an experiment plan, or which baseline comparisons are missing.
Multi‑turn tutoring:
Slightly higher final quality vs GPT‑5
Gains cluster where grounding and stage‑specific checks matter
Multi‑turn was the hardest setting because it punishes shallow routing mistakes. When the stage is misread early, the rest of the conversation drifts. METIS isn’t immune, but the failures were less frequent than the baselines in our scenarios.
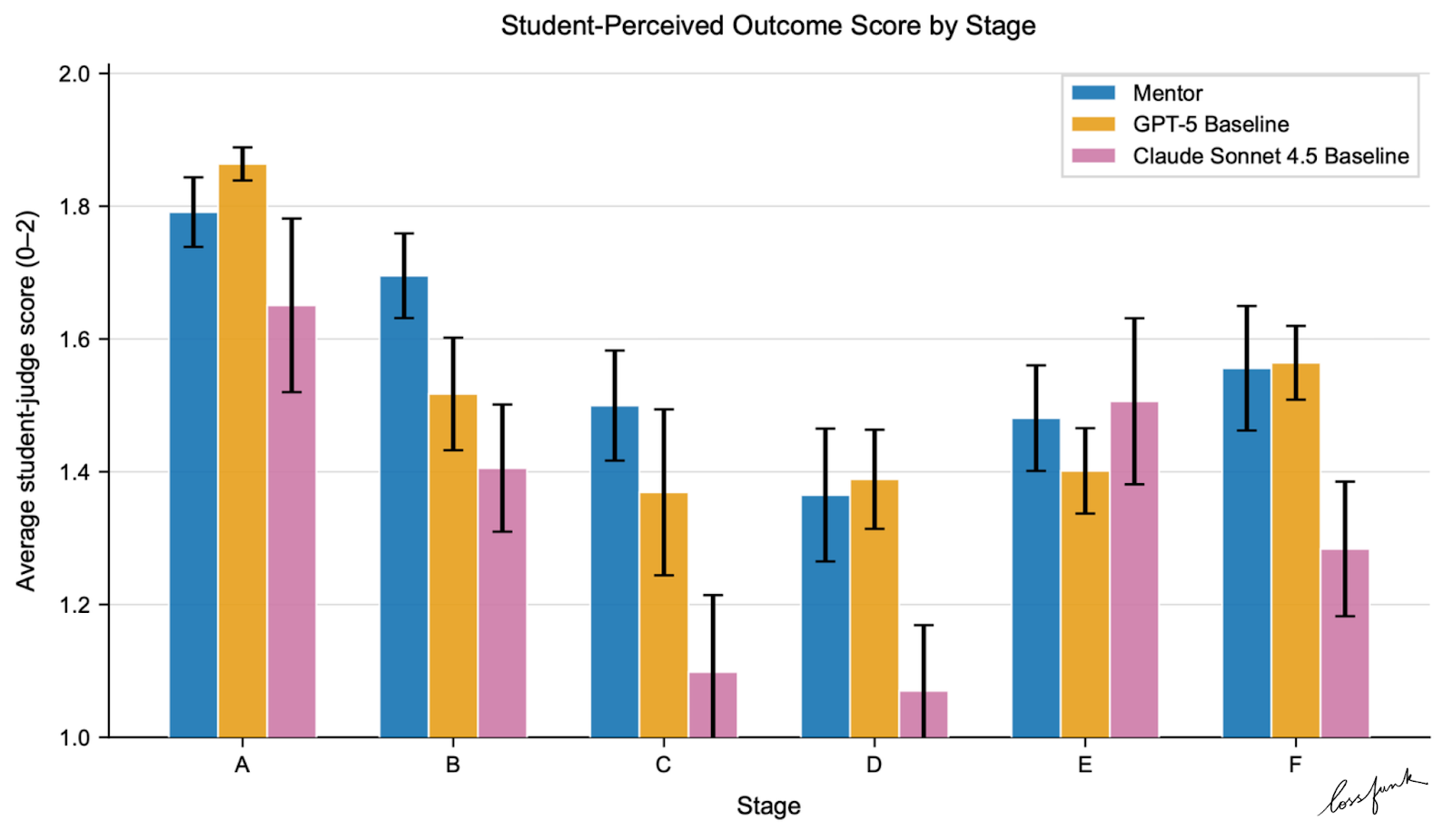
Why this worked
The biggest difference is structure. METIS doesn’t just answer; it tracks the student’s stage, routes tools that make sense for that stage, and enforces a response format that includes reasoning and justification.
That structure seems to matter most when students are already working with a draft and need concrete, actionable feedback. We saw the clearest lift in stages D–F, where students have material on hand and the mentor can ground advice in actual text, not just general tips.
We also saw fewer overconfident leaps. Stage awareness makes the system pause and ask for missing context instead of inventing it. It’s a small change in behavior, but it compounds over a multi‑turn exchange.
Limitations
There are still failure modes:
Premature tool routing
Shallow grounding
Occasional stage misclassification
We also don’t claim METIS is a full replacement for a human mentor. The goal is a reliable co‑pilot, a system that makes it easier for a student to move forward when they’re stuck. And like any tool, it still needs good prompts and honest inputs to work well.
Conclusion
METIS doesn’t solve mentorship, but it does make progress on the part that’s most brittle: knowing what a student needs next and saying it plainly. The tooling is useful, but the bigger win is the stage-aware framing that stops the system from jumping ahead.
We’re releasing prompts, scripts, and evaluation artifacts so others can reproduce results and extend the setup. A natural next step is learning the router from tool‑trace logs, running ablations across components, and validating the gains with real students over a longer horizon. If you use the artifacts, we’d love to see what breaks and what holds up.
Read the paper
Paper: https://arxiv.org/abs/2601.13075
AlphaXiv: https://www.alphaxiv.org/abs/2601.13075
Code: https://github.com/lossfunk/ai-research-mentor
Abhinav Rajeev Kumar, Dhruv Trehan, Paras Chopra — Lossfunk Research
abhinav.kumar@lossfunk.com | dhruv.trehan@lossfunk.com | paras@lossfunk.com
This is exaclty what research mentorship has been missing. The stage-aware routing is genius because it stops that frustrating cycle where you get solid advice that's just... not helpful yet. I remmeber being stuck at the methods stage and getting told to read more papers instead of help with experiment design. The document grounding in later stages sounds like it'd be a game changer for students who actually have drafts but need specific feedback.