Do LLMs know when they've gotten a correct answer?
We show they do and then use it to help cut reasoning cost (in tokens) by up to 50% without losing accuracy

This is a summary of our latest paper: Think Just Enough: Sequence-Level Entropy as a Confidence Signal for LLM Reasoning.
Read the full paper: https://www.alphaxiv.org/abs/2510.08146v3
TLDR:
Entropy of an LLMs output sequence correlates with correctness
We can estimate an entropy threshold from a few correct examples to apply during inference
At inference, applying at entropy threshold saves tokens (as we don’t continue to “reason”) while ensuring there’s no total accuracy impact
If you’ve used ChatGPT’s “Thinking” mode or Claude’s “Extended Thinking,” you’ve probably noticed something that AI keeps reasoning even when it already seems to have the answer. Sometimes that extra thinking helps but often, it’s just burning through tokens and your money unnecessarily.
As reasoning tasks become the dominant use case for large language models (LLMs), their inference costs are spiraling. Chain-of-thought prompting, self-consistency, and iterative refinement often demand multi-step, multi-thousand-token generations per query with no guardrails on when a model should stop.
But what if LLMs could tell when they were already confident enough in their answer and stop reasoning further?
Our new work, Think Just Enough, introduces a principled framework that uses Shannon entropy over token-level log probabilities as a confidence signal. This signal enables early stopping, reduces computational cost by 25 – 50 %, and maintains task accuracy across diverse reasoning benchmarks.
The core insight is simple yet powerful: models that have undergone advanced post-training (for example, reinforcement-learning-from-human-feedback or GRPO-style optimization) show a sharp drop in entropy once they reach a correct solution , a signal entirely absent in instruction-only models like Llama 3.3 70B.
Why We Needed This
Reasoning in modern LLMs is powerful but deeply inefficient.
Methods like Chain-of-Thought ,Tree-of-Thoughts and Self Consistency have extended models reasoning horizons but at the cost of thousands of unnecessary tokens. These approaches treat every question as equally difficult and never give the model a way to know when it has thought enough.
The result? Massive inference bills, higher latency, and wasted compute on easy problems that could have been solved in a fraction of the time.
Previous work has tried to fix this using heuristics (like stopping after a fixed number of reasoning steps) or adding learned classifiers to decide when to exit. But these methods either need retraining or fail to generalize across architectures.
Think Just Enough takes a different path: it introduces an information-theoretic measure that already exists inside every model’s output: its entropy.
No retraining, no extra parameters, no external labels. Just smarter use of what the model already knows about its own uncertainty.
Entropy as a Confidence Signal

Entropy measures how uncertain a probability distribution is.
For token log-probabilities lᵢ, we first normalize them:
pᵢ = exp(lᵢ) / Σ exp(lⱼ)
Then compute Shannon entropy for each token:
Hₜ = −Σ pᵢ · log₂(pᵢ)
Averaging over all tokens gives a sequence-level entropy (H̄).
Low H̄ means the model’s attention is focused on a few highly probable next tokens and it’s confident.
High H̄ means the model is uncertain and still exploring.
When the running average entropy H̄ falls below a threshold τ, the model stops reasoning and returns the answer.
We define four thresholding methods:
Entropy Mean (simple and conservative)
Bayesian Optimal (statistically grounded)
Information-Theoretic Optimal (maximizes mutual information)
Scale-Invariant Universal (generalizes across architectures)
The Llama 3.3 70B Ablation — When Confidence Doesn’t Emerge
To test how universal this signal is, we ran Llama 3.3 70B Instruct on the GPQA Diamond dataset.
Unlike GPT-OSS or Qwen models, Llama 3.3 was trained purely with instruction tuning no reinforcement-learning or reward optimization and it was pre Deepseek-r1 era that introduced and popularised the era of post training using RL.
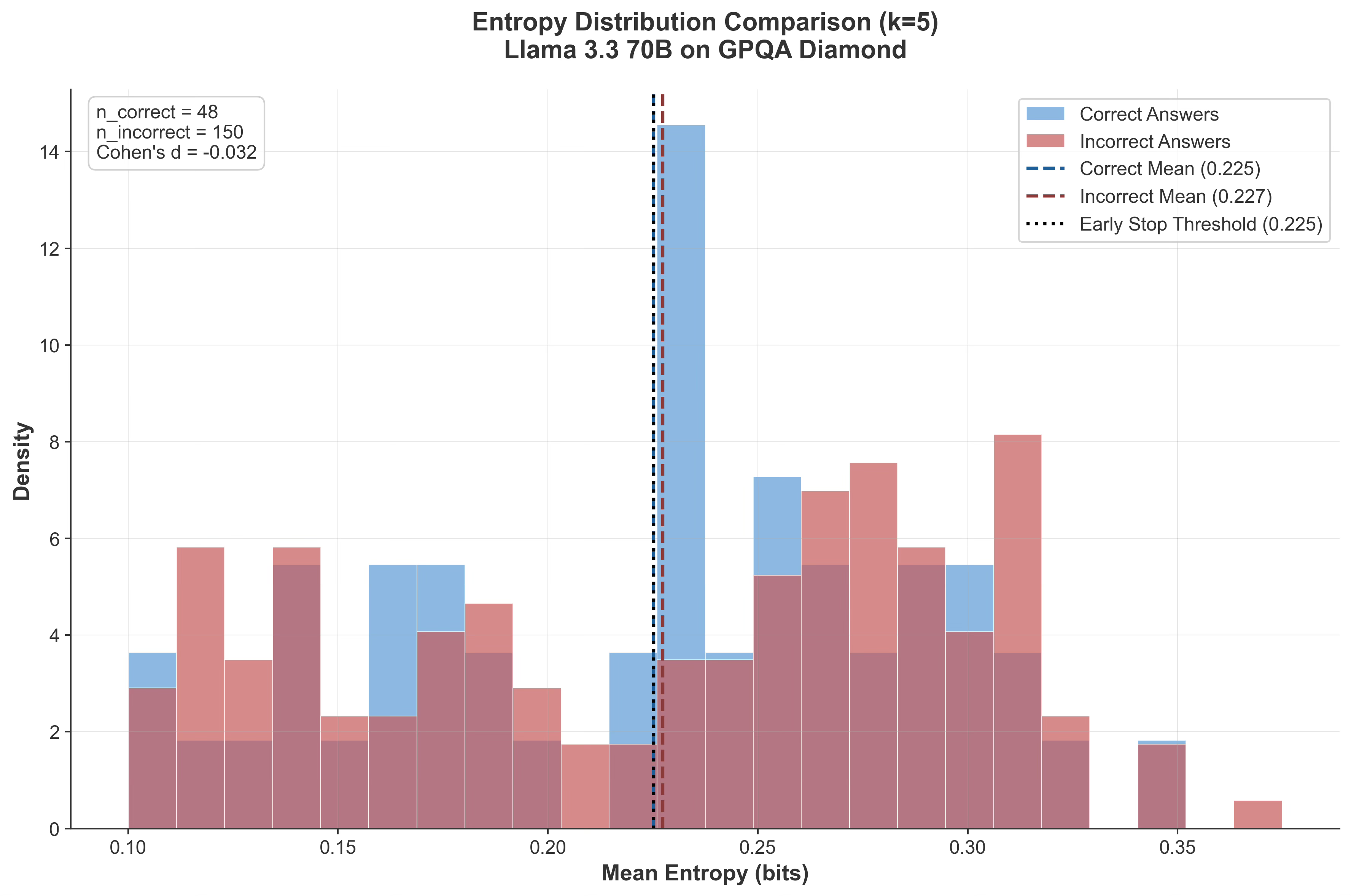
The results were telling. The entropy distributions of correct and incorrect responses almost perfectly overlap. There’s no discernible gap, no sign of emergent confidence. The model’s internal uncertainty doesn’t change whether it’s right or wrong.
This single ablation demonstrates a fundamental point:
Confidence calibration does not appear in instruction-tuned models. It emerges only after reward-based post-training, when the model learns to align low entropy with correctness rather than fluency.
Emergent Confidence in Post-Trained Models
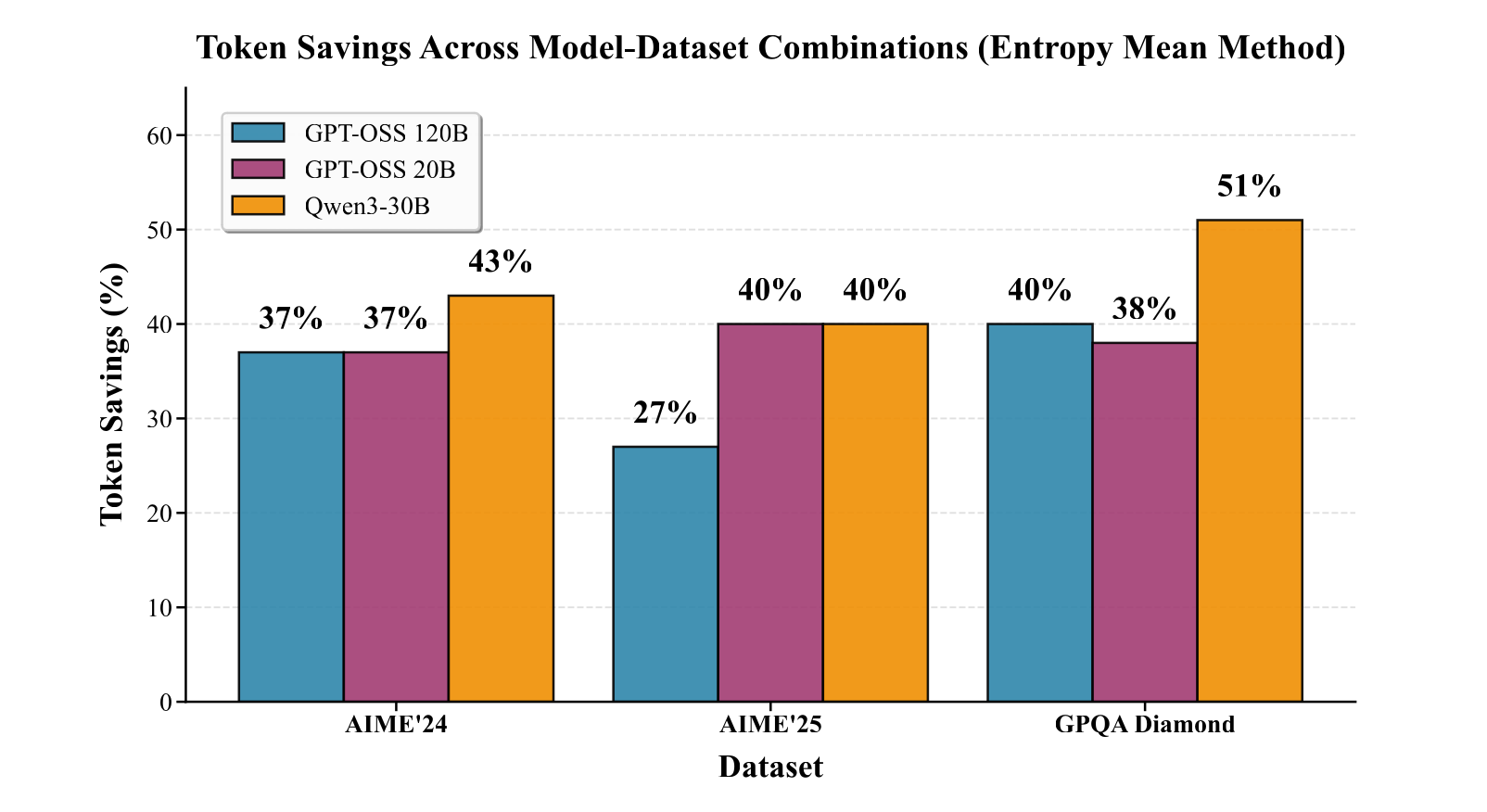
When we apply the same analysis to GPT-OSS 20B / 120B and Qwen3-30B-A3B instruct 2507, the difference is striking.
These reasoning-optimized models show a clear and consistent separation in entropy between correct and incorrect reasoning chains:
Distinct entropy gap (Cohen’s d ≈ 0.8 – 1.9)
Robust across multiple datasets and seeds
Thresholds calibrated with as few as 10 examples generalize across tasks
25 – 50 % token savings with zero loss in accuracy
These results show that post-training doesn’t just improve reasoning it gives models a genuine sense of when to stop.
Adaptive Token Budgeting
In real-world deployments, compute isn’t infinite. We often work under a fixed token or cost budget.
We extend our framework into a budget-aware allocator:
low-entropy (high-confidence) questions use fewer reasoning steps, while high-entropy (uncertain) ones get more.
This keeps the total budget constant but redistributes computation intelligently.
It’s the same principle humans use when problem-solving: don’t overthink on easy questions, spend time on the hard ones.
This dynamic scaling mirrors emerging trends like OpenAI’s “o3” and Claude’s “extended thinking” systems but achieved through a simple, interpretable metric rather than opaque reinforcement policies or learned heuristics.
Implications
For researchers: Entropy bifurcation offers a quantitative marker of reasoning maturity showing when a model begins to “know what it knows.”
For practitioners: A lightweight, plug-and-play early-stopping layer that reduces latency and cost without retraining.
For theory: A window into the emergence of confidence itself not as a hand-engineered feature, but as a learned alignment between internal uncertainty and external correctness.
Conclusion
Think Just Enough reframes reasoning efficiency: the goal isn’t to make models think longer, but to make them know when to stop.
By turning entropy into a confidence signal, we uncover a deeper structure inside modern reasoning systems , one that differentiates pattern imitators from truly self-calibrating models.
Certainty is learned, not innate.
Full Paper
Think Just Enough: Sequence-Level Entropy as a Confidence Signal for LLM Reasoning: https://www.alphaxiv.org/abs/2510.08146v3
Aman Sharma & Paras Chopra — Lossfunk Research
📧 aman.sharma@lossfunk.com | paras@lossfunk.com