Does spatial context make VLMs better game-playing agents?
And why noisy perception can make them worse.

This blog post provides a brief overview of our research paper “See, Symbolize, Act: Grounding VLMs with Spatial Representations for Better Gameplay,” accepted at the LM Reasoning Workshop at AAAI 2026.
Read the full paper here: https://arxiv.org/abs/2603.11601
TL;DR
Vision-language models can describe a game screen in detail. But can they act on what they see? We ran a structured experiment to find that out and specifically tested whether giving models explicit spatial information makes them better agents.
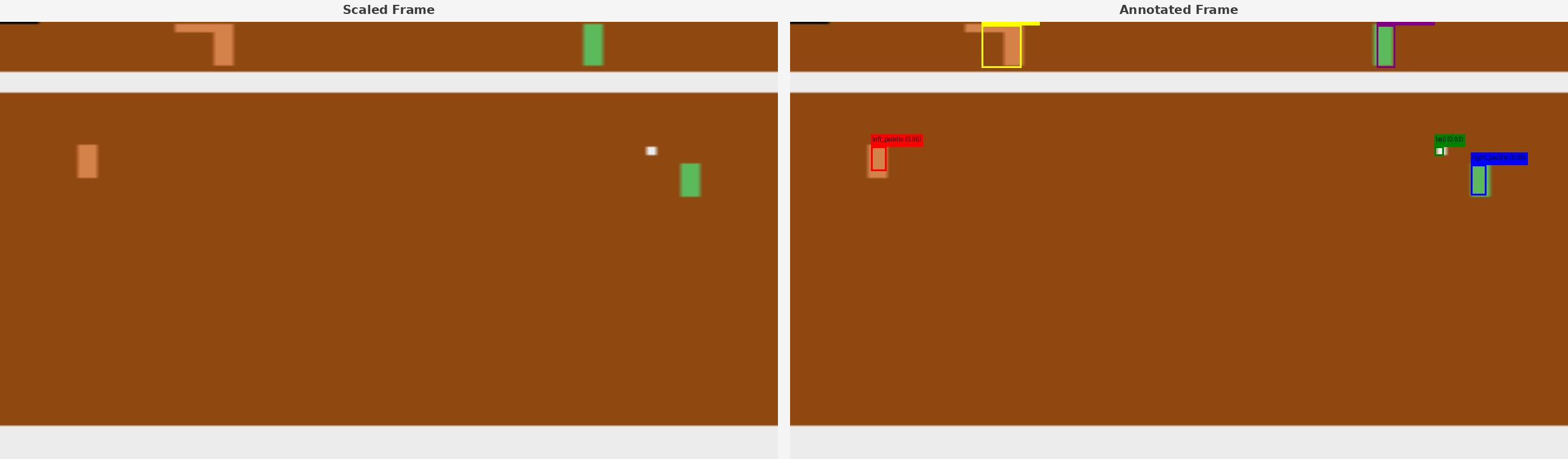
We tested Claude-4-Sonnet, GPT-4o, and Gemini-2.5-Pro on Pong, Breakout, and Space Invaders, each across four pipelines:
Frame-only: raw game screenshot, no additional context
Frame + Self-extracted symbols: model first localizes objects itself, then acts
Frame + Ground-truth symbols: perfect object coordinates pulled from game RAM via OCAtari
Symbols-only: ground-truth coordinates, no visual frame
Each pipeline ran for 600 frames per game. All three models, all four conditions.
Results
Ground-truth symbols consistently helped
When models received perfect coordinates, every model improved across every game. The pattern was consistent: better spatial information led to better decisions, regardless of which model was playing or which game was running.
Self-extracted symbols split the results entirely
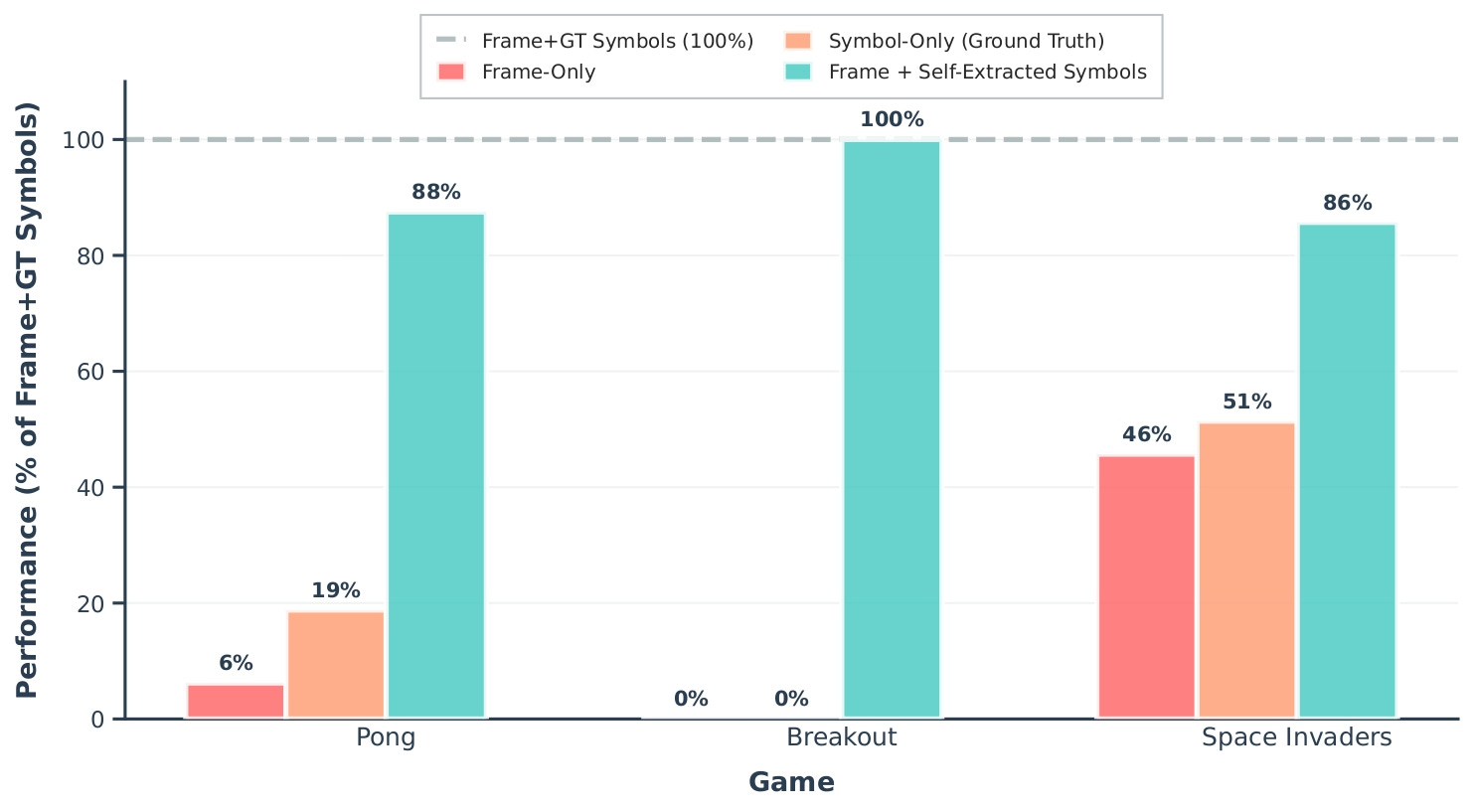
Claude improved in all three games with self-extracted symbols, reaching close to its ground-truth upper bound in every game.
GPT-4o and Gemini both degraded. In Pong, GPT-4o dropped noticeably from its frame-only baseline. Gemini fell in Space Invaders. The same pipeline that helped Claude hurt the other two.
Detection accuracy explains the split
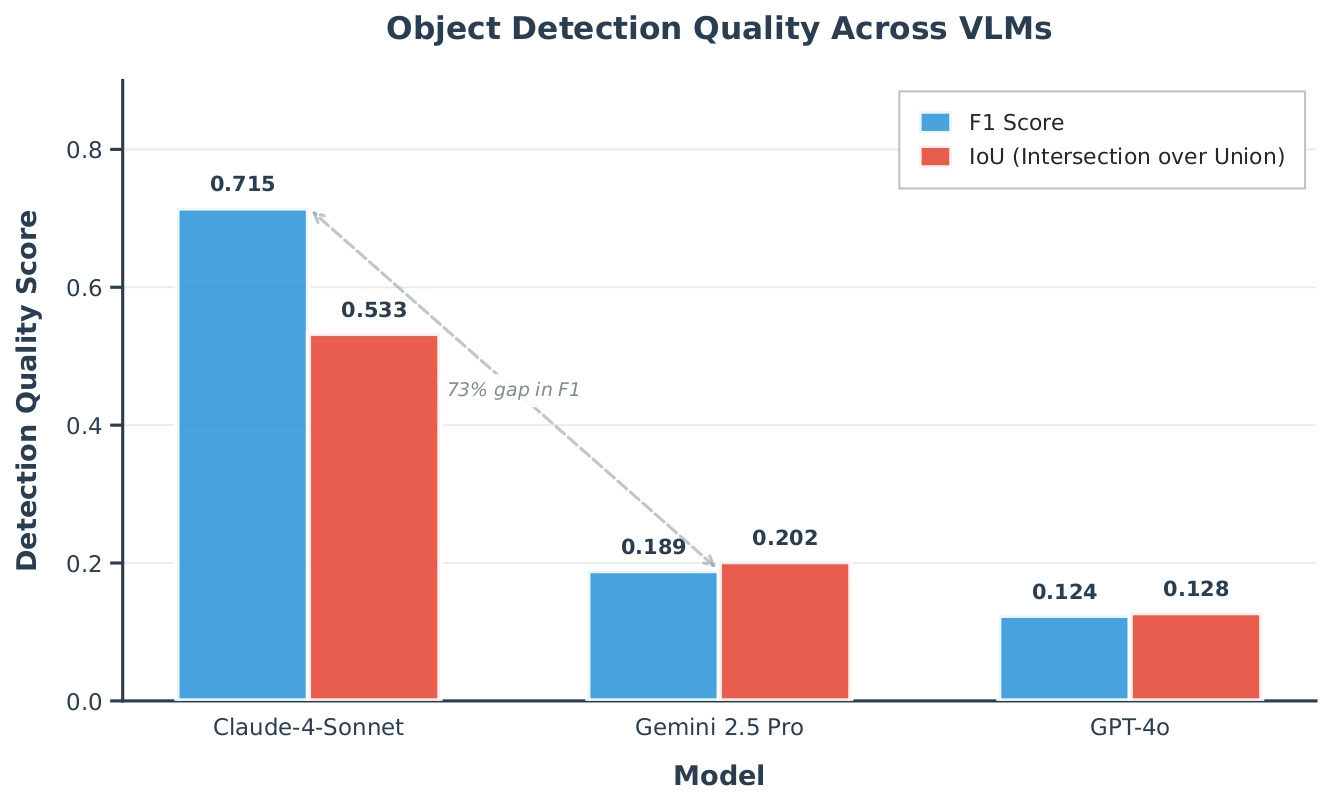
We measured object detection quality across 100 frames per game using OCAtari ground-truth annotations. Claude’s detection accuracy was substantially higher than both GPT-4o and Gemini. The gap was not marginal. It was the difference between a model that correctly locates most objects and models that miss the majority of them. When those errors get fed into the decision loop, they actively degrade performance relative to using no symbols at all.
The visual frame is not optional
Removing the visual frame generally hurt performance, but the effect was not uniform. For GPT-4o, the drop was severe across environments. However, in VizDoom and AI2-THOR (see below for environment), ground truth symbol-only performance exceeded Frame + Self-Extracted Symbols for some models (e.g., Claude and Gemini in VizDoom), suggesting that when self-extracted symbols are inaccurate, they can be more harmful than having no visual frame at all.
The same pattern holds in 3D environments
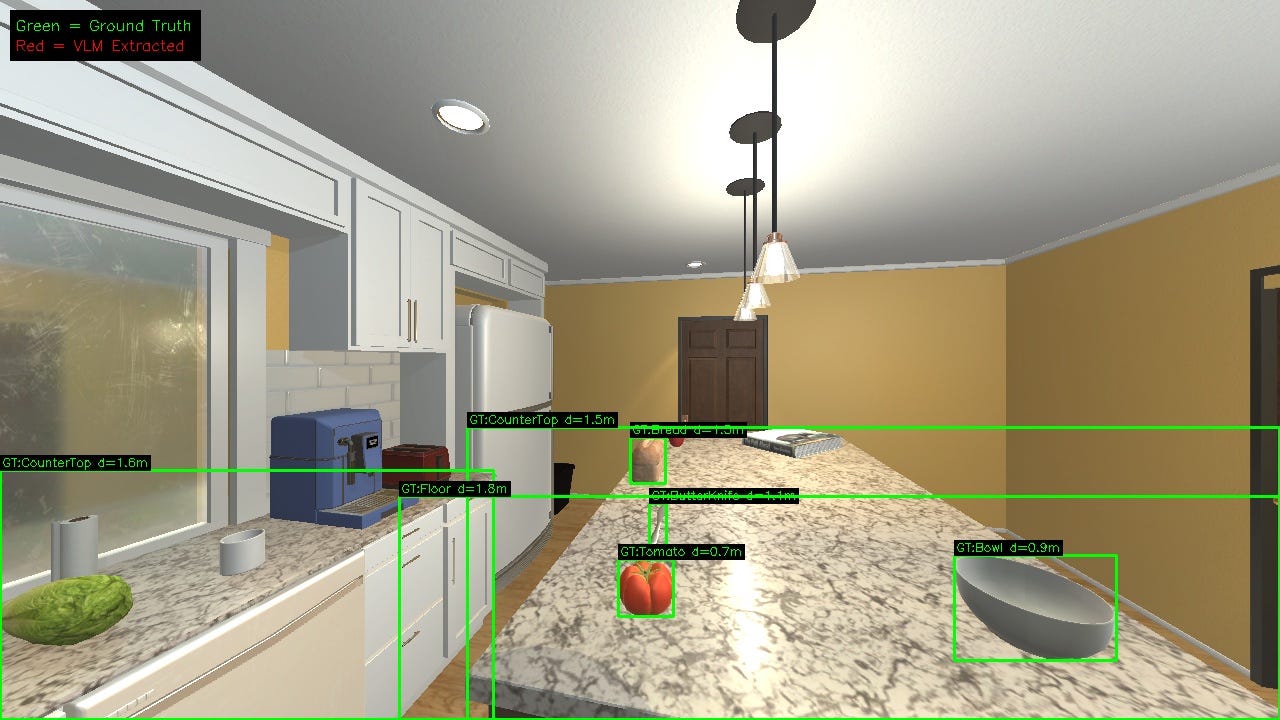
We ran identical experiments on VizDoom (first-person 3D shooter) and AI2-THOR (photorealistic kitchen task).
In VizDoom, Claude improved meaningfully with self-extracted symbols while GPT-4o and Gemini saw mixed results. In AI2-THOR, Claude gained with self-extraction, GPT-4o matched its GT baseline, and Gemini degraded.
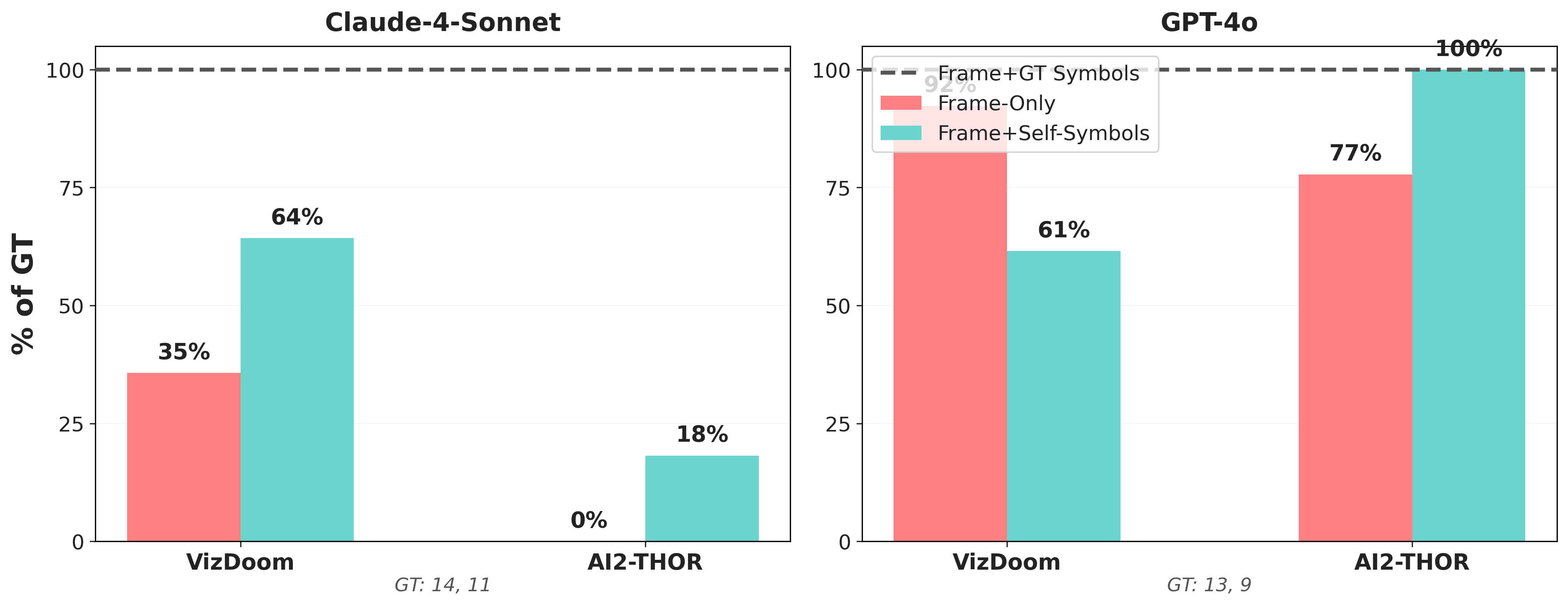
This shows that our finding is not an artifact of pixel-art graphics or Atari’s simplicity. It replicates across textured 3D scenes.
Takeaway
Symbolic grounding can help vision-language agents, but only when the symbols are reliable.
Across Atari, VizDoom, and AI2-THOR, we found a consistent pattern: when models receive accurate spatial information, their decisions improve. But when the symbols are noisy, the same pipeline can make performance worse.
Visual context generally improves performance, but the value of the visual frame depends on the quality of the symbolic information it is paired with. When self-extracted symbols are noisy, they can be more harmful than having no symbols at all.
The implication is simple: better perception unlocks better agents. Self-extracted symbolic grounding remains fragile until object detection becomes reliable.
Ashish Baghel, Paras Chopra — Lossfunk Research
ashish.baghel@lossfunk.com | paras@lossfunk.com
Really cool work. Working on something similar and had similar findings