How Many Agents Does it Take to Beat PyTorch?(surprisingly not that much)
Or: What happens when you give AI-agents a GPU and tell them to make it go brrr.


📌 Update (Feb 2026): Since this post, we published a new study, ISO-Bench: Can Coding Agents Optimize Real-World Inference Workloads? We built a benchmark of 54 real GPU optimization tasks from vLLM & SGLang, evaluated 4 coding agents, and found that agents understand the problem 87% of the time but can only execute the fix 18% of the time. Hard metrics alone overestimate capabilities by up to 20%.
Read more:
Paper: https://arxiv.org/abs/2602.19594
Website: https://ayushnangia.github.io/iso-bench-website/
Code: https://github.com/Lossfunk/ISO-Bench

We built a multi-agent system that writes specialized CUDA kernels by decomposing the problem into functional roles. On an H100 GPU, our generated kernels show significant acceleration over standard PyTorch implementations. Our custom softmax kernel achieves a 4.0x speedup, and our kernel for FusedLinearRowSum runs 2.5x faster, demonstrating our system's ability to produce highly optimized code for complex operations.
TL;DR
Multi-agent kernel generation works. We consistently generate kernels that significantly outperform some PyTorch baselines by splitting kernel optimization into specialized roles: synthesis, compilation, correctness, reasoning, and orchestration.:

Benchmarked on NVIDIA H100, FP32, mean of 100 runs
We worked over 50 kernels of KernelBench during development, with our multi-agent approach discovering optimization patterns that single-agent systems miss.
But first, a story about hubris...
The Problem: Working Alone Limits What You Can Do
Say you want to write super fast GPU code. You have the general idea and you have seen some examples online. But let’s be honest, you’ve never done it for real. It’s kind of like figuring it out as you go, because you may not have the deep expertise required.
You write something that looks reasonable. It compiles! It runs! It's... 40× slower than PyTorch.
This was us, initially.
The problem is that writing fast GPU code requires you to be good at several completely different things at once:
Math stuff: You need to understand what the operation is actually supposed to do and how to break it down into steps.
Hardware knowledge: GPUs are weird - you need to know how memory works, how threads are grouped, and dozens of other low-level details that can make or break performance.
Getting the right answer: Making sure your code actually works correctly with different data sizes, handles edge cases, and doesn't have subtle math errors that only show up later.
Making it fast: Finding where your code is slow, figuring out why, and fixing it - which often means starting the whole process over again.

Most existing approaches throw all of this at a single model and hope for the best. But what if we could specialize?
Multi-Agent Architecture
Multi-agent systems work better because they're basically how good teams already function in the real world. Instead of asking one person (or AI) to be amazing at everything, which never works out well, we bring in specialists who are actually good at their specific thing. This approach works because: Anthropic showed that their multi-agent system (Claude Opus 4 assisted by Claude Sonnet 4 subagents) outperformed a single-agent baseline by 90.2% in internal evals. Following this same principle, being inspired by work from Anthropic's multi-agent research and Microsoft's RD-agent, we built five specialized agents that look something like this:
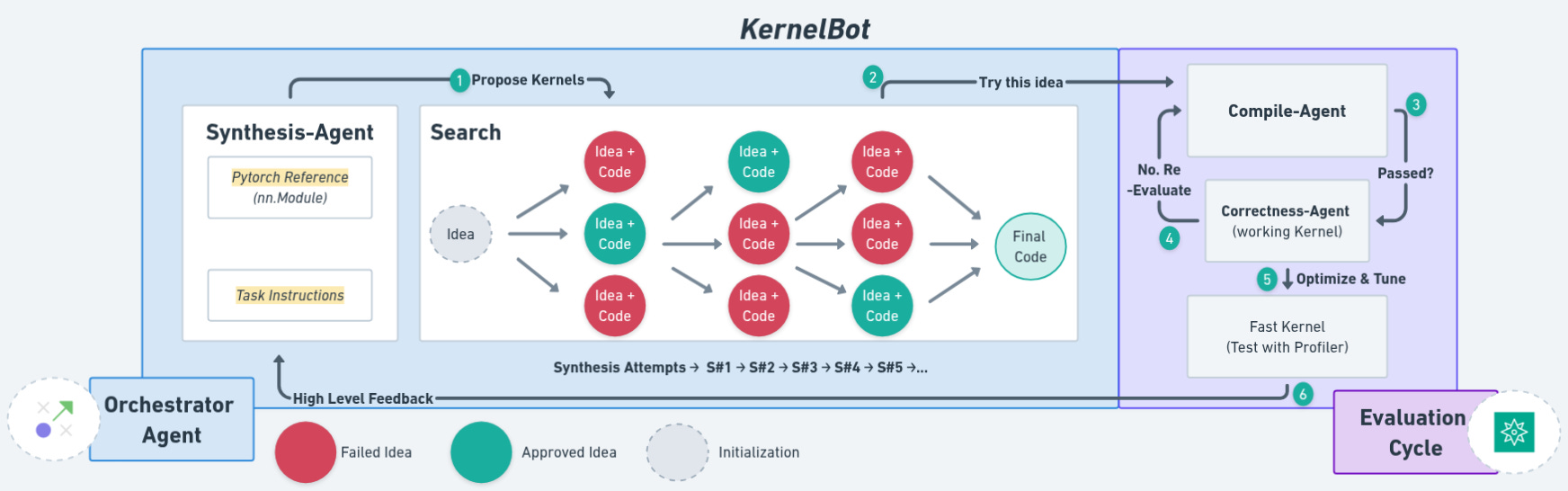
Synthesis-Agent
Role: Turns optimization ideas into actual CUDA kernels
Generates kernels from PyTorch reference code.
Implements specific optimization strategies (vectorization, shared memory patterns, etc.).
Maintains multiple kernel variants.
Has an unhealthy obsession with __restrict__ and __ldg().
Compile-Agent
Role: Makes sure things actually compile
JIT compiles kernels using PyTorch's load_inline
Provides detailed error feedback for syntax/compilation issues
Manages CUDA compilation flags and optimization settings
Secretly judges everyone's pointer arithmetic
Correctness-Agent
Role: Catches numerical bugs before they escape into the wild
Cross-checks kernel outputs against PyTorch reference.
Tests edge cases (different input sizes, boundary conditions, NaN handling).
Validates within tolerance thresholds (typically 1e-2 for FP32).
Has trust issues with floating-point math (for good reason).
Reasoner-Agent
Role: Generates optimization hypotheses
Analyzes performance bottlenecks using hardware intuition
Suggests specific optimization strategies based on GPU architecture
Learns from previous successful optimizations
Occasionally suggests impossible things that somehow work
Orchestrator
Role: Keeps everyone organized and on-task
Routes tasks between agents based on current workload
Delegation and context management: Decides who does what and makes sure everyone has what they need to get the job done.
Maintains kernel performance leaderboards (very competitive)
Prevents getting stuck: Decides when to terminate optimization rounds and stops agents from falling into the same optimization traps over and over.
Prevents agents from getting into infinite optimization loops
The Method: Branching Search (Or: How to Avoid Local Minima Hell)
Traditional kernel optimization looks like this:
Write kernel → Test → Fix bugs → Optimize → Test → Optimize more → ...This is fine, but it often gets stuck. You spend 20 iterations micro-optimizing shared memory layout when you should have been using a completely different algorithm.
Our approach branches at each step instead:
Idea 1 → Implementation A → Test A ┐
Idea 2 → Implementation B → Test B ├→ Performance Arena → Winners
Idea 3 → Implementation C → Test C ┘Here's how it works:
Idea Generation: ReasonerAgent proposes multiple optimization hypotheses in natural language
"What if we use float4 vectorization for memory coalescing?"
"Can we fuse the linear layer with the row reduction?"
"Should we try warp-level primitives for the softmax reduction?"
Parallel Implementation: SynthesisAgent implements each idea as separate kernel variants
No sequential bias - each idea gets a fair shot
Maintains multiple codepaths simultaneously
Sometimes accidentally creates beautiful disasters
Compilation Step: Compile-Agent filters out kernels with build errors
Surprisingly, this eliminates about 30% of candidates.
Provides detailed feedback for common CUDA gotchas.
Has seen every possible template instantiation error.
Correctness Hell: CorrectnessAgent validates numerical accuracy
Why do we care about numerical accuracy? Because unstable kernels don’t just break down, they just quietly compound the errors when scaling on real data and you’d never know.
Another 20% of kernels fail here (floating-point is hard).
Tests with different input distributions, sizes, edge cases.
Maintains a hall of shame for spectacularly wrong kernels.
Performance: Kernels race on GPU; winners seed next round
Only the fastest survive to reproduce.
Performance differences often surprise everyone.
Sometimes the "obviously bad" idea wins.
This branching approach prevents getting stuck in local optima and explores diverse optimization strategies simultaneously. It's like parallel evolution, but for CUDA kernels.
Optimization Categories Discovered
Our agents consistently discovered optimizations in six key areas:
Memory Access Optimization: Coalesced loads, vectorized operations (float4), avoiding bank conflicts
Shared Memory Management: Efficient reduction patterns, warp-level primitives, memory reuse strategies
Asynchronous Operations: Overlapping computation with memory transfers, hiding latencies
Numerical Stability: Max subtraction in softmax, robust reduction algorithms, epsilon handling
Hardware Utilization: Maximizing occupancy, efficient warp scheduling, register pressure management
Algorithmic Improvements: Kernel fusion, eliminating redundant passes, computational graph optimization
The Hall of Fame (And Shame)
LayerNorm ASAP (as stable as possible):
Our agents produced a vectorized LayerNorm that's both fast and numerically stable. The key insight? Two-pass shared memory reductions with float4 I/O:
// The money shot: vectorized accumulation
const float4* x4_ptr = reinterpret_cast<const float4*>(X + row * cols);
for (int idx = tid; idx + 3 * blockDim.x < cols4; idx += 4 * blockDim.x) {
for (int k = 0; k < 4; ++k) {
float4 v4 = __ldg(x4_ptr + i);
sum += v4.x + v4.y + v4.z + v4.w;
sq_sum += v4.x*v4.x + v4.y*v4.y + v4.z*v4.z + v4.w*v4.w;
}
}
// ... warp reductions and normalization magic followsResult: ~1.3× speedup over eager.
Agent comment: "We tried 47 different shared memory layouts before finding the one that didn't cause bank conflicts. Worth it."
Fused Linear → RowSum:
Instead of separate linear and reduction operations, our agents discovered kernel fusion:
// Single pass: compute linear transformation and row reduction in one go
float acc = 0.f;
for (int col = threadIdx.x; col + 3 * blockDim.x < cols; col += 4 * blockDim.x) {
for (int k = 0; k < 4; ++k) {
acc += __ldg(X + row * cols + c) * __ldg(Wc + c);
}
}
// Warp reduction magic happens here...Result: ~2.5× speedup over eager.
Agent comment: "Why launch two kernels when one kernel do trick?"
Softmax:
Classic three-pass softmax (max, exp-sum, normalize) with shared memory optimization. The agents independently rediscovered the importance of max subtraction for numerical stability:
Result: ~4.0x speedup over eager.
Agent comment: "We spent 3 rounds debugging NaN outputs before remembering that exp(800) is not a small number."
Diagonal Matmul:
We were so excited about our 40× speedup that we nearly posted it on Twitter. Then we actually looked at what was happening and it was pretty stupid what KernelBench had done.
What went wrong:
We were comparing the wrong things. The original code was using torch.diag(A) @ B, which secretly creates a huge N×N matrix just to multiply a diagonal. Instead of a simple multiplication, PyTorch was doing way more work than it needed to.
Don’t trust even the benchmarks. Turns out KernelBench had a bug where it wasn't running the full loop, so even the slow version looked fast.
Once we fixed the original code to actually do the right math (A.unsqueeze(1) * B) and fixed the test loop, our "amazing" speedup dropped to a sad 1.2× and in some cases even ~0.5x slowdown. Small gains.
Moral: Benchmark twice, tweet once. PyTorch already crushes trivial ops.
What We Learned (The Hard Way)
Why Multi-Agent Works Better
Tries more ideas at once: Instead of testing one approach at a time, we explore multiple optimization paths simultaneously and often find solutions that linear thinking would miss
Everyone's good at their thing: Each agent focuses on what they know best, so you get real expertise instead of one system trying to be okay at everything
Catches problems early: Multiple validation steps mean broken or wrong code gets filtered out before it wastes time
Unexpected discoveries: Sometimes the agents find clever optimizations that even surprise us - combinations we wouldn't have thought to try
Where We Dominate
Complex operations: Multi-stage algorithms benefit from collaborative optimization
Memory-bound workloads: Agents excel at discovering efficient shared memory patterns
Beating torch.compile: For operations where PyTorch's JIT hasn't been heavily optimized
Where We're Still Learning
Simple operations: PyTorch eager is already highly optimized.
Benchmarking discipline: Easy to fool yourself with wrong problem sizes or unfair comparisons.
Hardware-specific tuning: Need better integration with architecture-specific features (Tensor Cores, etc.).
The Road Ahead: More Agents, More Problems
Immediate Improvements
Single-pass algorithms: LayerNorm with Welford's algorithm for better numerical stability
Mixed precision: BF16/FP16 optimizations for modern hardware
Multi-kernel fusion: Cross-operation optimization (the holy grail)
Hardware-specific agents: Specialists for Tensor Cores, different GPU architectures
The Bigger Picture
We see multi-agent kernel generation as part of a larger trend toward specialized AI systems. Rather than building ever-larger monolithic models, we can create focused agents that collaborate on complex technical tasks.
The same principles could revolutionize:
Hardware design: Agents specializing in different aspects of chip architecture
Systems optimization: Database query planning, compiler optimization passes
Scientific computing: Numerical method selection and parameter tuning
Software engineering: Code review, testing, performance optimization
Giving Back to the Community: Enhancing KernelBench
Since we were building on KernelBench anyway, we ended up fixing a bunch of stuff and adding features that seemed useful. Rather than keep it to ourselves, we're contributing everything back. Here's what KernelBench-v2 brings to the table:

Try It Yourself (We Dare You)

Our multi-agent kernel generation system is built on top of the KernelBench framework. While we're still cleaning up the code for release, the core ideas are straightforward to implement:
Define specialized agent roles with clear interfaces and responsibilities
Use a better branching search instead of sequential revision to explore the optimization space
Validate at every step (compilation, correctness, performance) to catch problems early
Let agents learn from successful optimization patterns across problems
The future of AI systems may not be about building bigger models, but about building smarter collaborations.
And remember: if your kernel does not beats PyTorch by at least 2×, you're probably doing something wrong. Or PyTorch is just really, really good.
Built with inspiration from Sakana AI's CUDA Engineer and Stanford SAIL's fast kernels. Special thanks to the Hazy Research team for showing us that technical blogs can have personality. All kernels from our multi-agent system are open-sourced and available on GitHub: Flash-Kernels. Feel free to contribute and hack!
Shikhar and Ayush are Lossfunk researchers who created this project, while at Lossfunk. They’re now starting a company around it.
this looks really promising! I do wonder though, would the ideation strategies for writing these kernels need to change depending on the gpu being optimized for? for instance, an algorithm might be compute-bound on a high-core-count GPU like an H100, but memory-bound on lower-end consumer gpus. curious how the system handles this variability across hardware tiers.