Making Large Language Models Speak Tulu: Structured Prompting for an Extremely Low-Resource Language
We use a structured 5-layer prompt to get GPT, Gemini and Llama to generate grammatically correct Tulu, a low-resource Dravidian language, with no fine-tuning at all.

This is a summary of our paper accepted at the LoResLM Workshop at EACL, 2026: Structured Prompting for Low-Resource Language Generation: A Case Study in Tulu
Preprint: https://arxiv.org/abs/2602.15378v1
Code: Tulu Structured Prompting on Github
Authors: Prathamesh Devadiga, Paras Chopra
TL;DR:
We build a ~2,800-token structured prompt that gets GPT and Gemini to generate Tulu instead of defaulting to Kannada
The prompt has 5 layers: identity, negative constraints (~50 banned Kannada words with Tulu alternatives), grammar tables, few-shot examples, and a self-check
Negative constraints alone cut Kannada contamination roughly in half. Telling the model what not to say matters more than telling it what to say
A custom romanization scheme drops tokenization from 3.2 to 1.4 tokens per word, fitting more into the context window
Ablations (V1 through V4) confirm each layer adds value; full system hits ~14% contamination and ~74% grammar accuracy
I speak Tulu at home. About 2 million people do, mostly along the coast of Karnataka. But if you ask GPT or Gemini to “respond in Tulu,” you get Kannada response every single time. The main reason that this happens is because these two languages share a script and a lot of surface vocabulary, and since Kannada has orders of magnitude more text on the internet, the model just defaults to it.
The obvious fix to this problem might seem fine-tuning, but there’s barely any digitised Tulu data to train on, and we didn’t have compute to spare. So we tried something simpler: what if we just wrote a really good prompt?
Turns out that a single prompt if structured the right way, is enough to get the model to stay in Tulu, use correct grammar, and avoid Kannada words. No training, no adapters, no LoRA. This post walks through how it works and why.
Tulu is a Dravidian language, closely related to Kannada. It has its own grammar: Subject Object Verb (SOV) word order, 8 cases, an inclusive/exclusive “we” distinction, verb forms that conjugate for gender. But it has almost no presence in training corpora. When a model sees “respond in Tulu,” it pattern-matches to the nearest thing it knows, and that’s Kannada.
The failure mode in this scenario is very subtle. The grammar looks roughly right, the sentences are fluent but half the vocabulary is wrong. The model says naanu (Kannada for “I”) instead of yaan (Tulu). It says hogu (”go” in Kannada) instead of po: A Kannada speaker might not even notice, but a Tulu speaker will.
So the core problem is vocabulary contamination from a related, higher-resource language. That’s what we designed the prompt to fix.
We build the prompt in a fixed order. Every layer has one job, and the ordering matters (constraints before grammar, not after).
The first layer is identity (~200 tokens). It tells the model who it is: a native Tulu speaker, responding only in Tulu, using our romanization scheme (diacritics for retroflexes, vowel length markers, velar nasal). No Kannada script, no English. Sounds basic, but without it the model has no anchor. It needs to know what language it’s supposed to be thinking in.
The second layer is negative constraints (~600 tokens), and this is where most of the work happens. We give the model a list of ~50 high-frequency Kannada words and say: never use these. Each one is paired with the correct Tulu word.
NEVER USE USE INSTEAD
naanu yaan (I)
ninu ii / iir (you)
yenu yena (what)
hogu po (go)
helu panla (say)
illa ijji (no)
The wording in the actual prompt is aggressive: “CRITICAL,” “NEVER USE,” “NON-NEGOTIABLE.” We put this block before the grammar section because in our testing, constraints placed early in the context window have more effect than the same constraints placed later.
Here’s how those 50 constraints break down by word category:
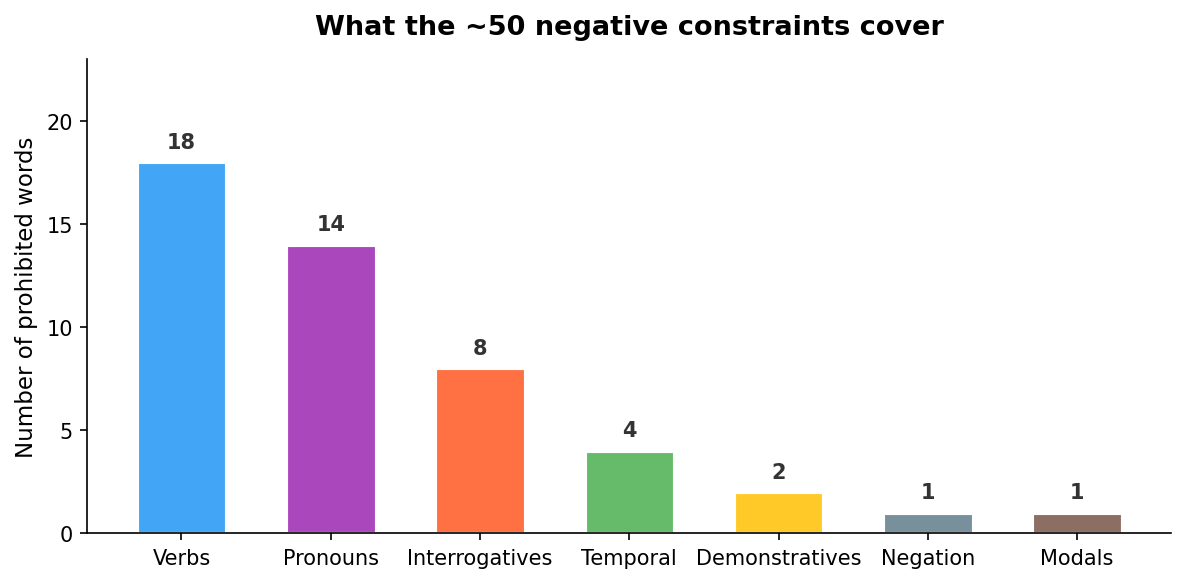
Verbs and pronouns make up most of the list. Makes sense: they’re the highest-frequency words, and the ones where Kannada and Tulu diverge the most.
This single layer drives the biggest improvement. When we add it (V3), contamination drops sharply compared to V2 (grammar only).
The third layer is grammar (~1,200 tokens). We write out Tulu grammar explicitly: pronoun paradigms, verb conjugation tables (present/past/future for common verbs), all 8 case markers with allomorphy rules, and SOV word order with examples.
The model can then compose new sentences from these rules instead of falling back on Kannada patterns.
The fourth layer is few-shot examples (~600 tokens). 10 to 15 question-answer pairs in Tulu. Greetings, daily routines, family, time. They demonstrate correct vocabulary, grammar, and word order in context. Nothing fancy, just real usage.
The fifth layer is self-verification (~200 tokens). A short checklist the model is told to run through mentally before responding: Did I avoid all prohibited Kannada words? Are verb forms correct? Is the order SOV? Are case markers right? Does the model actually do this? Hard to say. But in practice, adding this layer reduces errors at the margin.
One thing worth mentioning: romanization.

Tulu is traditionally written in Kannada script, but Kannada script tokenizes poorly: about 3.2 tokens per word with standard tokenizers. Our romanization (with diacritics for retroflex consonants and vowel length) brings that down to about 1.4 tokens per word. The prompt fits more content in the same context window, and it’s easier to distinguish Tulu words from Kannada words during evaluation since we’re matching against a romanized watchlist.
So does it actually work? We test four versions, each adding one more layer to the prompt:

V1 (baseline) is just “respond in Tulu.” High contamination, weak grammar. V2 adds grammar, which helps some. V3 adds the negative constraints, and that’s the big jump: contamination drops sharply. V4 is the full system with few-shot and self-verification on top, and it’s the best on both metrics.
We also ran ablations the other way wherein, we start with the full system and remove one component at a time. From our experiments, we notice that removing constraints hurts the most and removing self-verification hurts the least. Grammar and few-shot are somewhere in between.
The pattern is clear, that is, telling the model what not to do is more effective than telling it what to do, at least for this kind of vocabulary contamination problem.
We also tried generating synthetic Tulu Q&A pairs with the same setup. The idea is simple: use the structured prompt to generate questions and answers, then filter for quality.

Each generated pair is scored by 3 independent judge calls on grammar, purity (no Kannada leakage), naturalness, relevance, and cultural fit. Only pairs averaging 3.5 or higher are kept. Combined with the seed examples, this gives us a usable dataset without any manual annotation.
Some honest caveats from this experiment: the grammar checker in our evaluation is lightweight. It checks for known verb forms and case markers, but it can’t do full morphological parsing, so grammar accuracy numbers should be read as lower bounds. We don’t have ground-truth Tulu data at scale, so BLEU or similar metrics aren’t meaningful here. Long prompts cost money and latency, ~2,800 tokens of system prompt on every call adds up and we haven’t tested whether this transfers to other model families. It works on GPT and Gemini; results on open models might differ.
If you’re working with a low-resource language that’s close to a high-resource one, the contamination problem we describe here probably sounds familiar. The approach is simple: build a structured prompt that sets identity, explicitly bans the most common wrong-language words, gives real grammar, shows examples, and asks the model to double-check.
It won’t replace fine-tuning when you have the data and compute for it. But when you don’t, a well-designed prompt goes further than you’d expect.
This is such a good work. An excellent example for actual meaningful research. Kudos to the team