Practical tips on building LLM agents
Resources we stumbled upon to help build your next agent

At Lossfunk, many of our projects are experimenting with using LLMs in an agentic way. Previously, we wrote about how the temptation to build multi-agents is misguided.
Since then, we’ve stumbled upon more resources and thought of summarizing insights common among them.
(Well, if multiple independent people say the same thing, it must have an element of truth, isn’t it?).
Resources we’ll be referring to:
Context Engineering for AI Agents: Lessons from Building Manus
Why I'm Betting Against AI Agents in 2025 (Despite Building Them)
[Insight #1] Chunk tasks for your agent so that each atomic task would take less than 10-15 minutes for a human
This is because success probability for an LLM on a task is directly related to how long it takes for a human to do it. See this graph from the METR study.
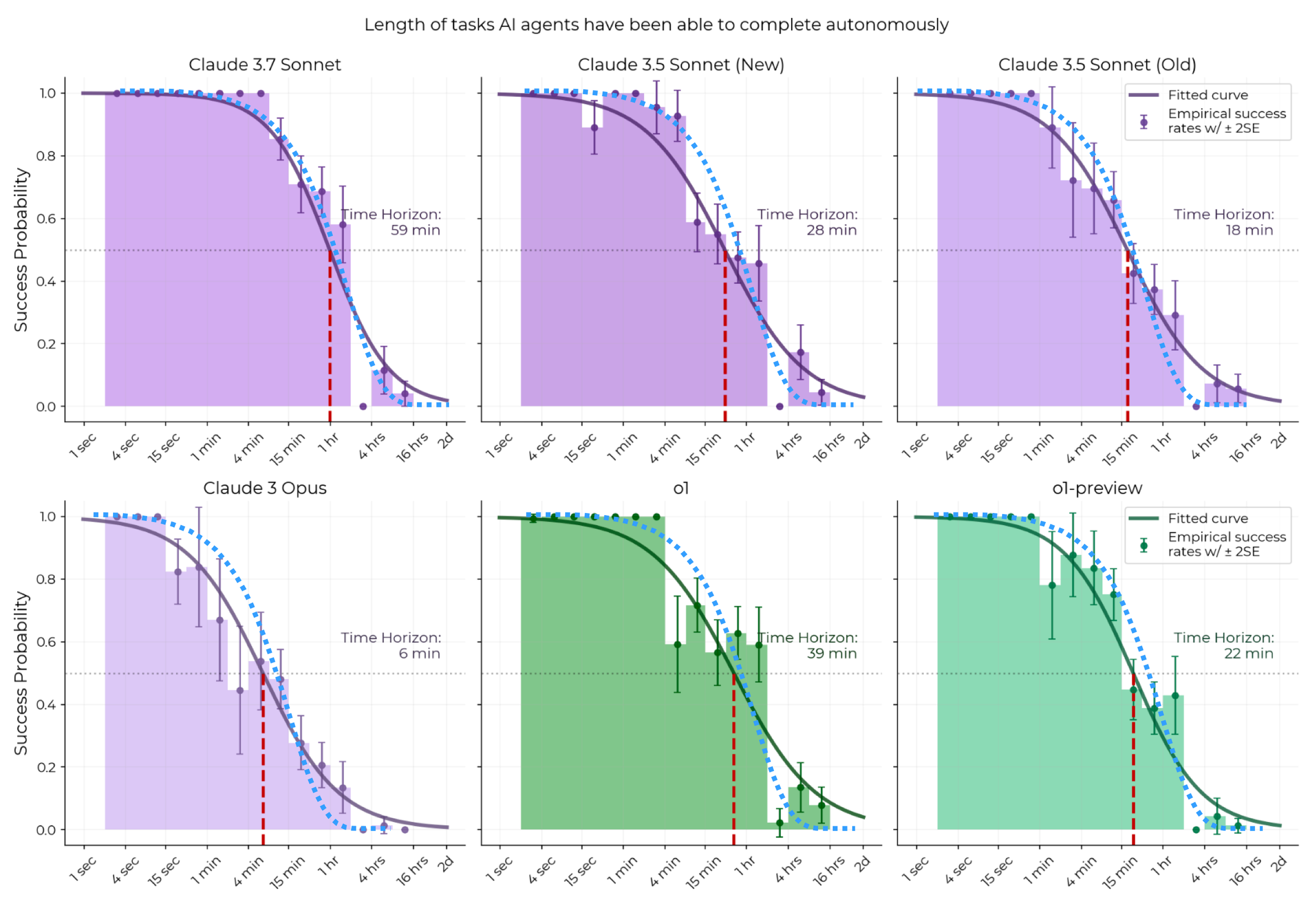
Notice how success probability hovers around 90% for tasks that take humans 10 minutes to complete.
This (separate) article also reiterates the same:
The Story Breakdown - Everything in 15-30 minute chunks. Why? Because that's roughly how long before Claude starts forgetting what we discussed ten minutes ago. Like a goldfish with a PhD.
[Insight #2] Have one LLM do everything by utilising long context windows fully
Context is everything for LLMs. The more context you give to an LLM, the better it’ll be able to perform.
In the podcast with Cline’s creators, importance of long contexts was quite evident when they mentioned that RAG approaches to indexing and querying code is effectively dead as RAG gives fragments that confuses the model. Instead, much better is to include entire files in the context.
In fact, a recent paper showed that if you put all files into a context window of a model, you get the same performance as an “agentic” flow on the popular software engineering benchmark SWE-bench-Verified.
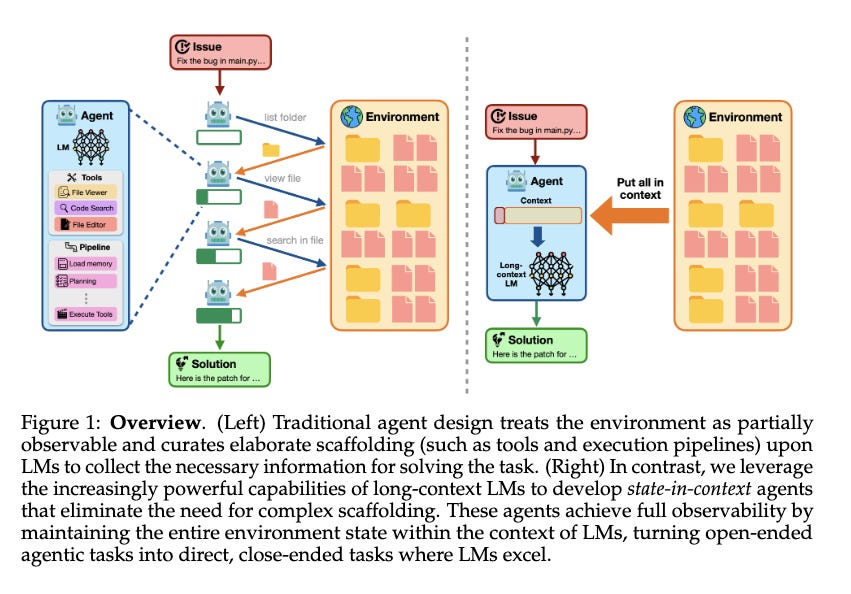
In the Cline podcast (mentioned above), they also also talked about how earlier versions of Cursor used a cheaper fast-diff model that would take the code suggested by LLMs and create a diff out of it for applying it on the code. This lead to compounding errors: first LLM generated code could be erroneous and then fast-diff models would introduce errors. Today, such fast-diff models are replaced by having LLM itself generate a diff using SEARCH and REPLACE blocks. This has reduced the error rate from 20% to less than 5% now for generating a DIFF.
General insight here is that base models are getting smarter by the day, so any cost-saving workarounds are going to cause a drop in performance.
Ultimately, you get what you pay for!
[Insight #3] Long horizon tasks have a tendency to fail, so you need to invest in building a solid verification system for each step
As this separate article suggests, the more steps in your task, the higher likelihood that errors will compound and ultimately your agent will fail.
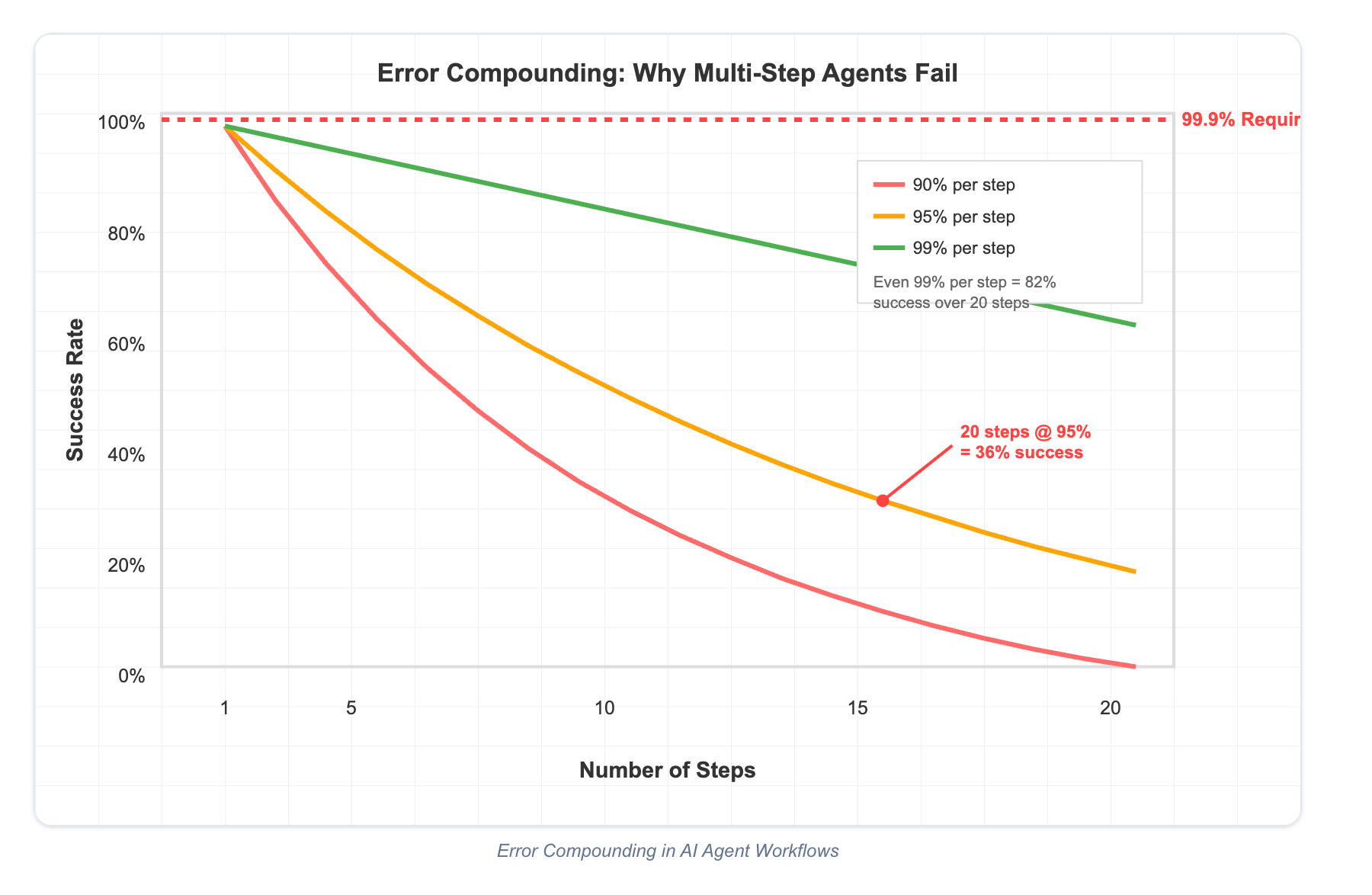
How to work around it? Some tips:
Keep your tasks isolated (if you can!). Have a flow where LLMs perform stateless functions that don’t depend significantly (or at all) on previous tasks
Have a verification step after each task. Your LLM should be able to know clearly what is success or failure for this task! Otherwise, it’ll just keep moving forward and the errors will balloon.
[Insight #4] Treat LLMs as geniuses with total amnesia, so find ways to repeat in the context what it needs to do and how to do it well
From this article, we also learned that it’s a good idea to repeat the todo list for the agent for a long running task. This is to prevent agent forgetting what is to be done as LLMs have a tendency to forget earlier tokens as the context window grows.
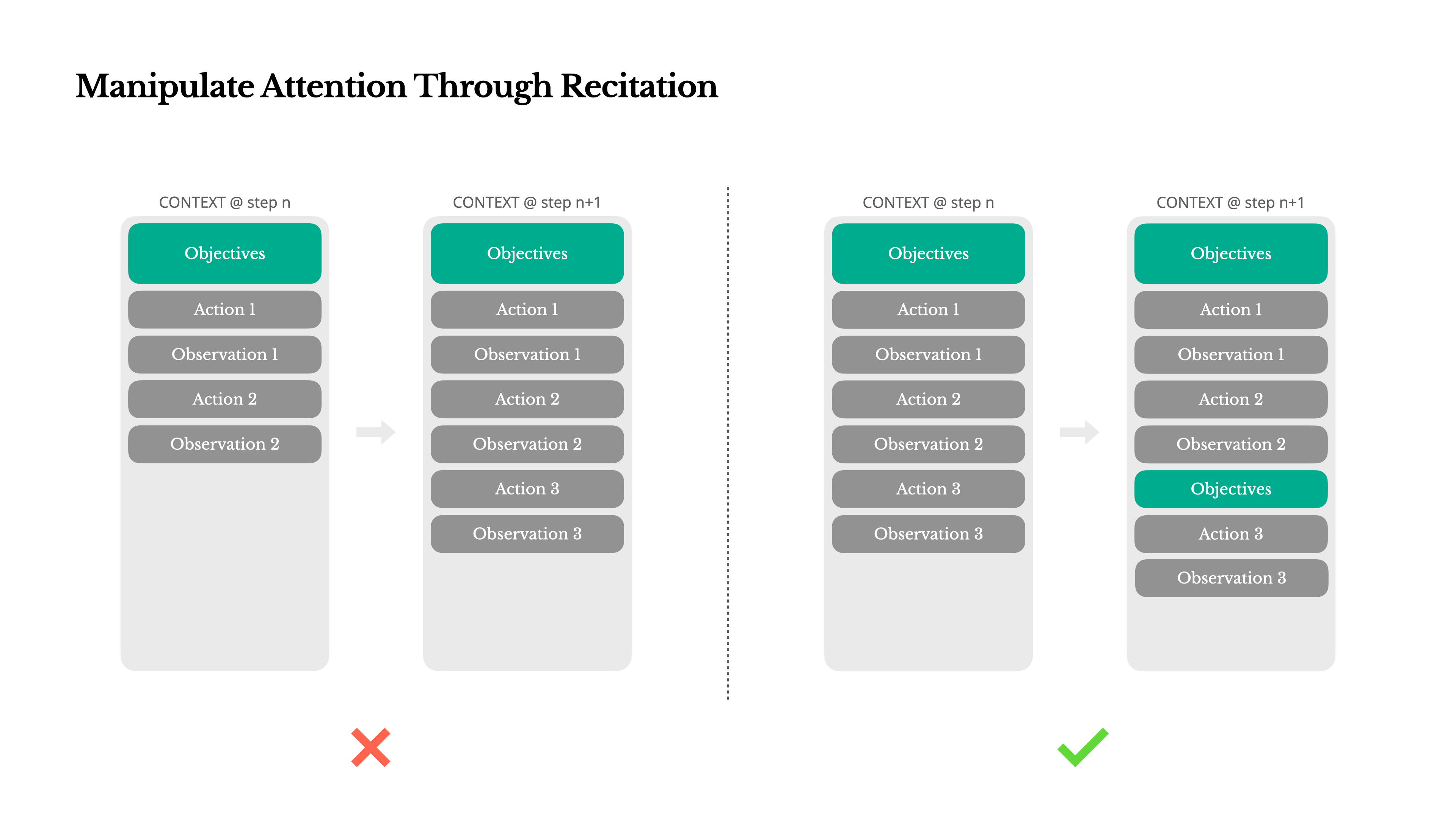
In a similar vein, this article suggests giving the model instructions to first read all the important files related to the task at hand. Interestingly, the model is instructed to write to these files also as it solves problems, ensuring compounding of learnings as it solves problems.

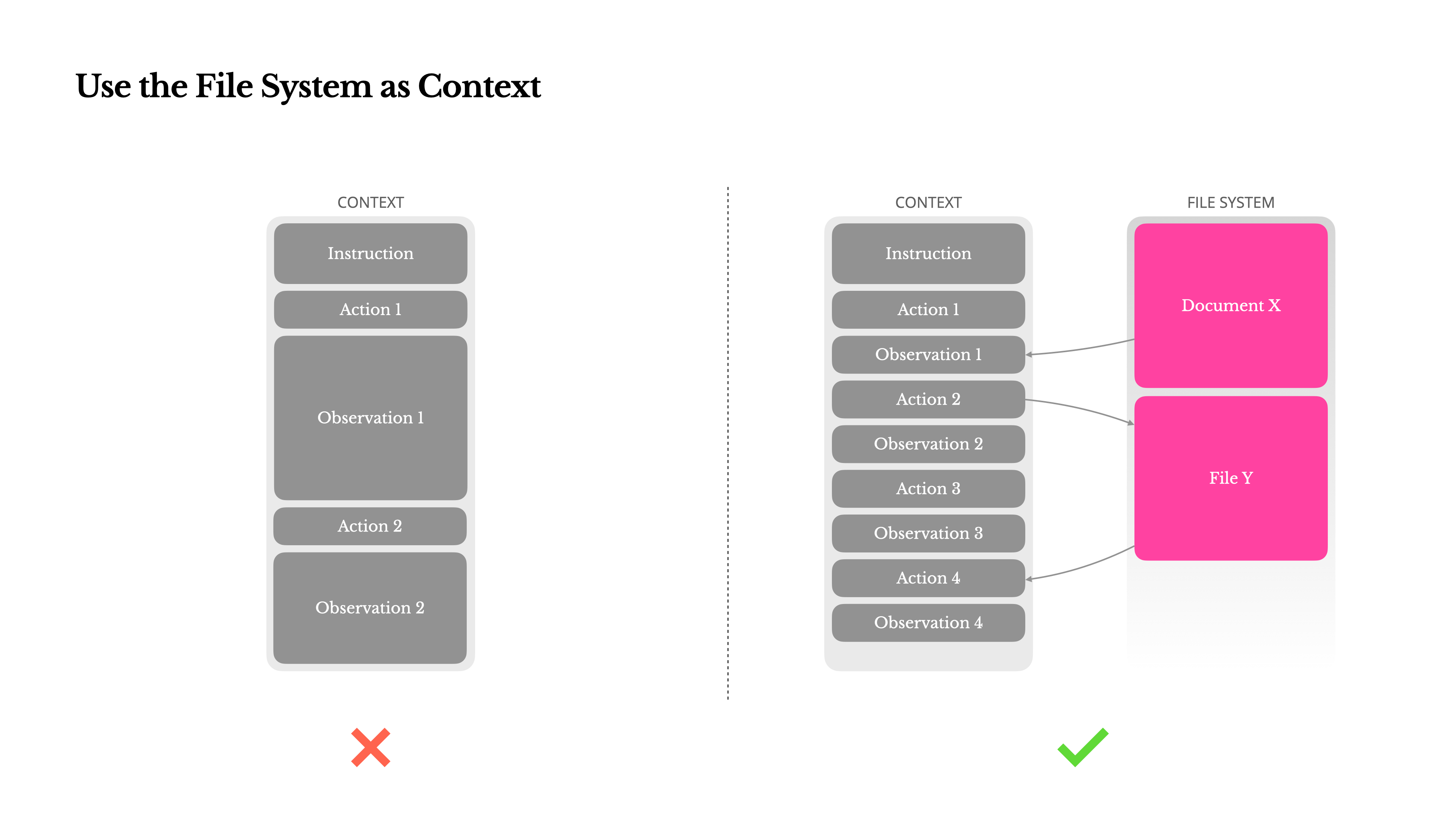
Note how these files are NOT put in the context window of the LLM, rather what’s mentioned is simply instructions to read these files. This brings us to the next insight…
[Insight #5] Give the LLM read/write tools and let the LLM build its own context window
As models become good at tool-calling, it makes more and more sense to treat them as agents that can do things as a human would do. And just as humans depend on tools to get things done, so do these LLMs.
From this article, notice how context stuffing has now shifted to letting agent read and write files.
LLMs are great at using tools, but building tools for LLMs is an art in itself, as this article suggests.
Tool calls themselves are actually quite precise now. The real challenge is tool design. Every tool needs to be carefully crafted to provide the right feedback without overwhelming the context window. You need to think about:
How does the agent know if an operation partially succeeded? How do you communicate complex state changes without burning tokens?
A database query might return 10,000 rows, but the agent only needs to know "query succeeded, 10k results, here are the first 5." Designing these abstractions is an art.
When a tool fails, what information does the agent need to recover? Too little and it's stuck; too much and you waste context.
How do you handle operations that affect each other? Database transactions, file locks, resource dependencies.
[Insight #6] Cost rises quadratically for multi-turn agents, so never change context (to ensure you hit cache)
Cost becomes a real concern for production agents, and the surprising bit is that your token cost doesn’t just increase linearly. It rises quadratically!
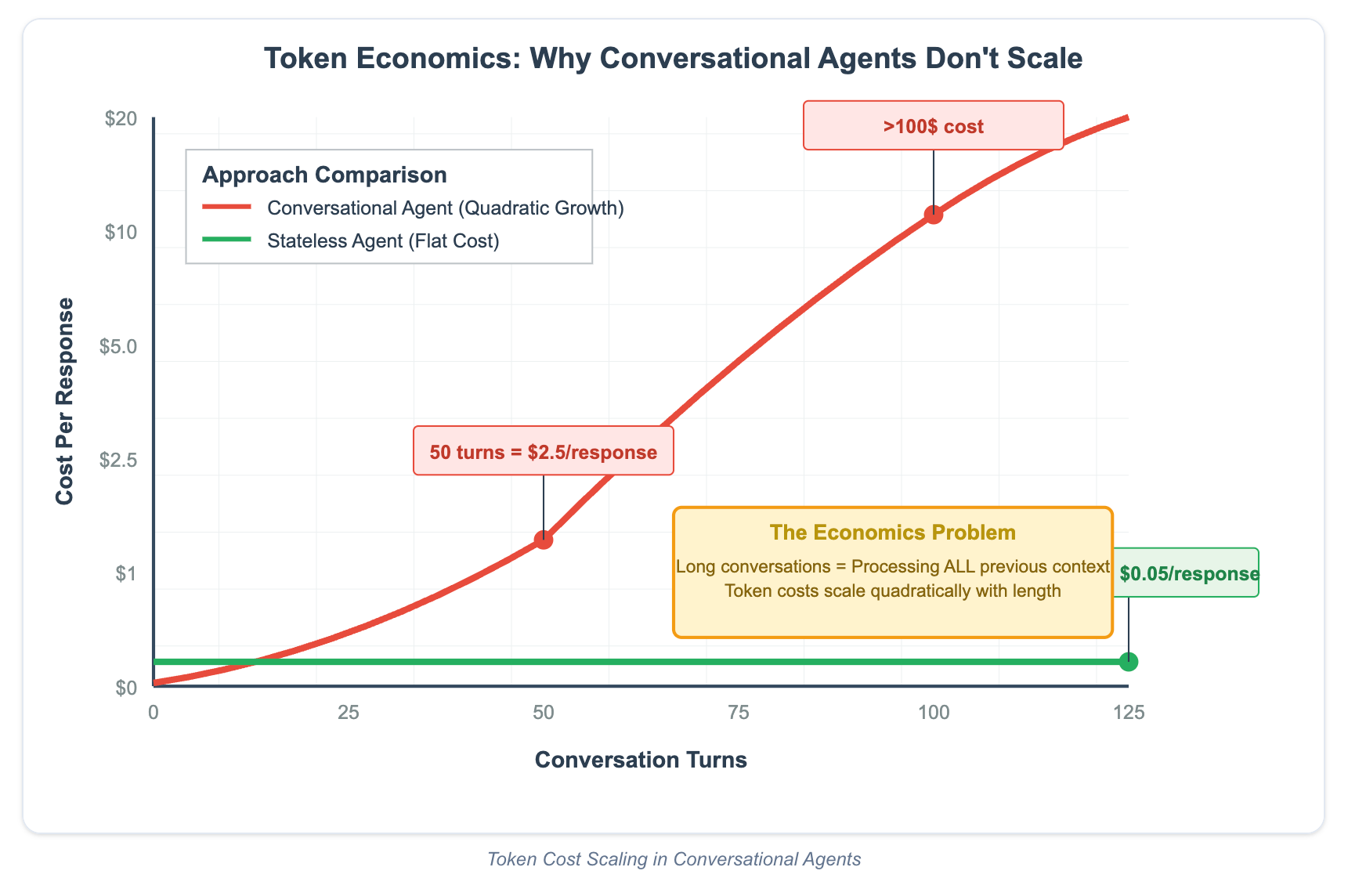
At 50 turns of your multi-turn agent, you’ll be burning $2.5/response, which rises to $100/response at 100 turns! Ouch.
This is why you always always append to the context, but must NEVER change it midway. This is to help you hit the KV cache of previous conversation, and doing that drops the cost to 1/10th.
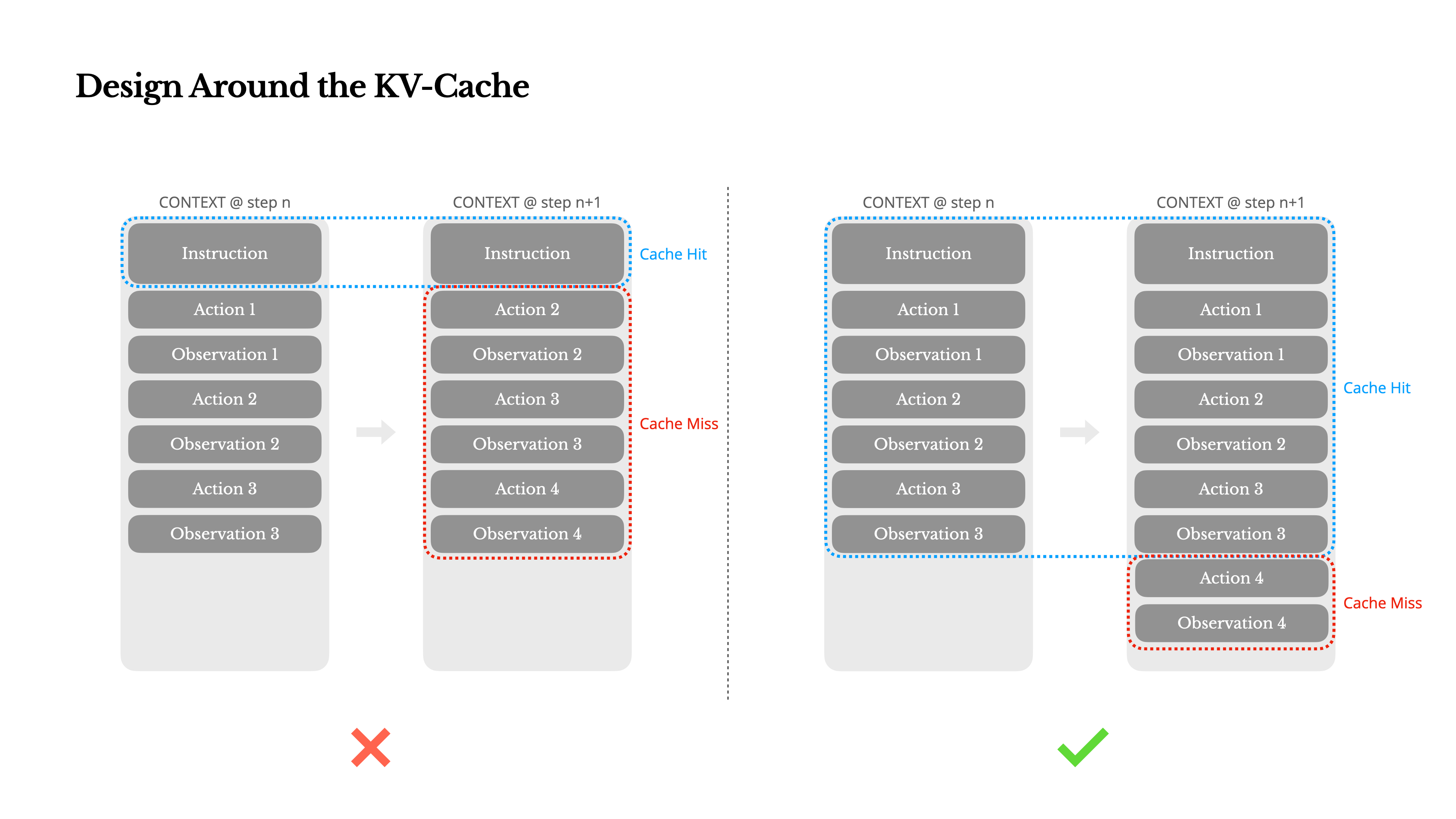
Even with 1/10th the cost, it seems like $10/response at the 100th turn is too high. So, unless your task justifies it, don’t naively assume your users will be okay to spend hundreds of dollars on your agent every day. Think and design better. Costs matter!
That’s about it! Hope you liked our insights!
The author, Paras Chopra, is founder and researcher at Lossfunk.
Great insights. It felt like speed dating with the papers. Thanks 🙏
It is all good according to current capabilities of models, how do you build product that it can incorporate those advances in the model