Sequential scaling outperforms parallel scaling for LLMs
AI reasoning just got a upgrade: At the same compute cost, sequential thinking—iteratively refining ideas—beats parallel "crowdsourcing" in 95.6% of tests, boosting accuracy by up to 46.7%.

This is a summary of our latest paper: The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute.
Read the full paper: https://arxiv.org/abs/2511.02309
TLDR:
Sequential scaling outperforms parallel self-consistency in 95.6% of configurations at matched compute, with accuracy gains up to 46.7% relative gains.
We introduce inverse-entropy weighted (IEW) voting, a training-free method to boost sequential accuracy by weighing chains inversely to their entropy.
IEW is optimal in 96.7% of sequential and 100% of parallel setups, establishing it as the universal aggregation strategy.
Sequential framework achieves up to 25.6 percentage point gains as token budgets increase, via unique mechanisms like error correction and context accumulation.
Rethinking AI Reasoning: The Inference-Time Revolution
In the whirlwind of AI progress, we’ve poured resources into bigger models: more parameters, endless data, slicker architectures. But lately, the spotlight’s shifted to inference-time scaling: pumping extra compute not into training, but into the model’s “thinking” phase when it’s actually solving problems. OpenAI‘s o1 model in 2024 kicked this off, showing how extra deliberation time could crush tough tasks in math and science. Hot on its heels, models like DeepSeek-R1 in 2025 amped up chain-of-thought methods to push boundaries even further.
The go-to strategy? Parallel reasoning, thanks to the paper Self-Consistency Improves Chain of Thought Reasoning in Language Models from Wang et al. (2022). It spins up multiple independent thought chains and picks the winner by majority vote. Makes sense on paper: Independent paths add diversity, filtering out errors through an ensemble effect.
But what if we turned that upside down? With the same token budget (our yardstick for compute), could fewer, deeper chains each refining the last outperform the parallel pack? That’s the puzzle we unpacked in our latest preprint. After crunching numbers across five top open-source models and three brutal benchmarks, the verdict is clear: Sequential reasoning doesn’t just hold its own, it dominates in almost every scenario. No fancy fine-tuning needed; just clever prompting to tap into what LLMs already do well. Let’s dive in.
Parallel vs. Sequential: Breaking Down the Approaches
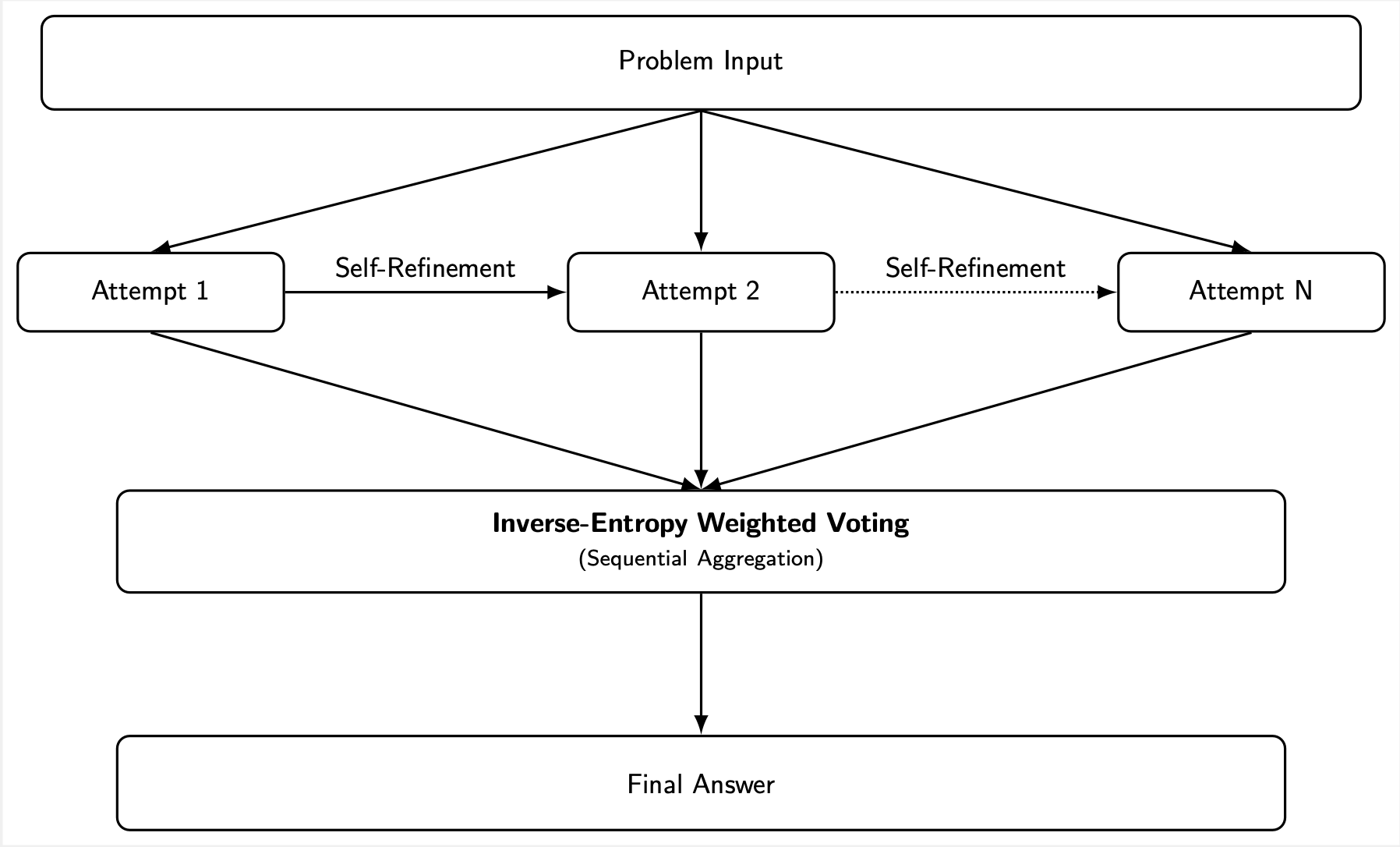
Quick refresher: Parallel reasoning is like a brainstorming session where everyone works in silos. The model generates several standalone chains for the same problem, each starting fresh. At the end, you tally votes on the answers using majority voting. It’s efficient for parallelism and depends on different reasoning approaches to reduce errors.
Sequential reasoning flips to iteration mode. It starts with a first stab at the problem. Then, loop back: prompting further improvements or corrections. Every step inherits the full history, fostering self-fixes, layered insights, and double-checks. Imagine editing a draft solo versus a group yelling ideas without hearing each other.
Why the edge for sequential? Parallel chains are isolated; they can’t cross-correct. Sequential thrives on real evolution: Spotting math errors mid-stream, stacking context for deeper dives, and verifying hunches across passes. Our framework (see the figure above) spells this out, turning raw LLM intelligence into a refinement loop topped with smart voting with no additional training required.
The Setup: Models, Benchmarks, and Fair Play
We went all-in on rigor. Models spanned families and scales: GPT-OSS-20B and 120B (OpenAI’s open-weight mixture-of-experts models optimized for reasoning), Qwen3-30B and 235B (Alibaba’s Qwen3 series MoE models with advanced multilingual and reasoning capabilities), and Kimi-K2 (Moonshot AI’s trillion-parameter MoE model excels in agentic tasks and long-context reasoning). Everything ran through OpenRouter‘s API with uniform tweaks like 0.7 temperature for balanced creativity.
Benchmarks hit hard reasoning spots:
AIME-2024/2025: High-stakes math puzzles demanding multi-step logic (answers: integers 0-999).
GPQA-Diamond: PhD-level brain-teasers in physics, chemistry, and biology.
Creative tasks (for ablation): Joke creation to probe ideation beyond pure logic.
Fairness first: Matched compute across the board. For 6 chains, that’s 24,576 tokens total (6 × 4096). Parallel distributes them across independent chains while sequential accumulates them progressively.
The Big Reveal: Sequential’s Crushing Lead
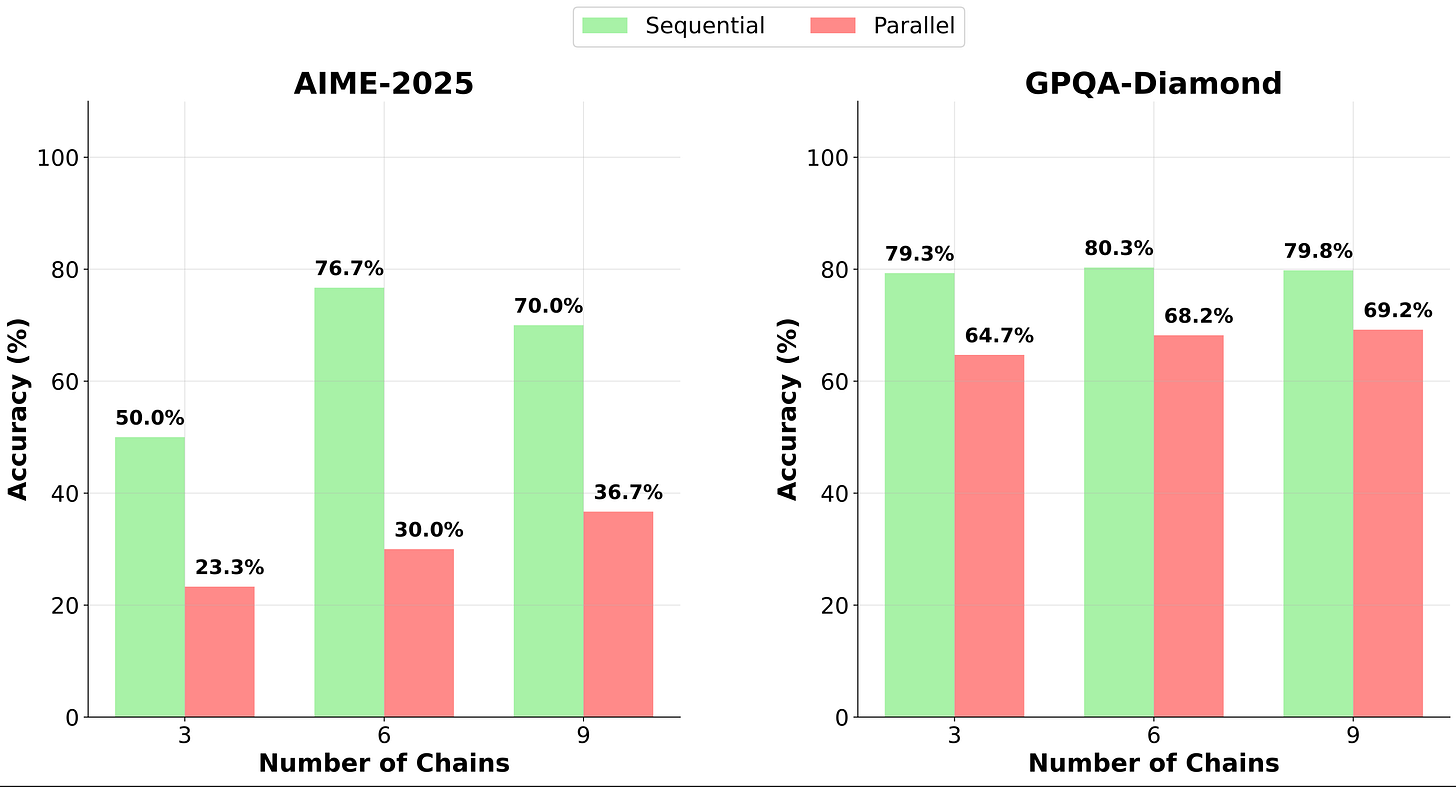
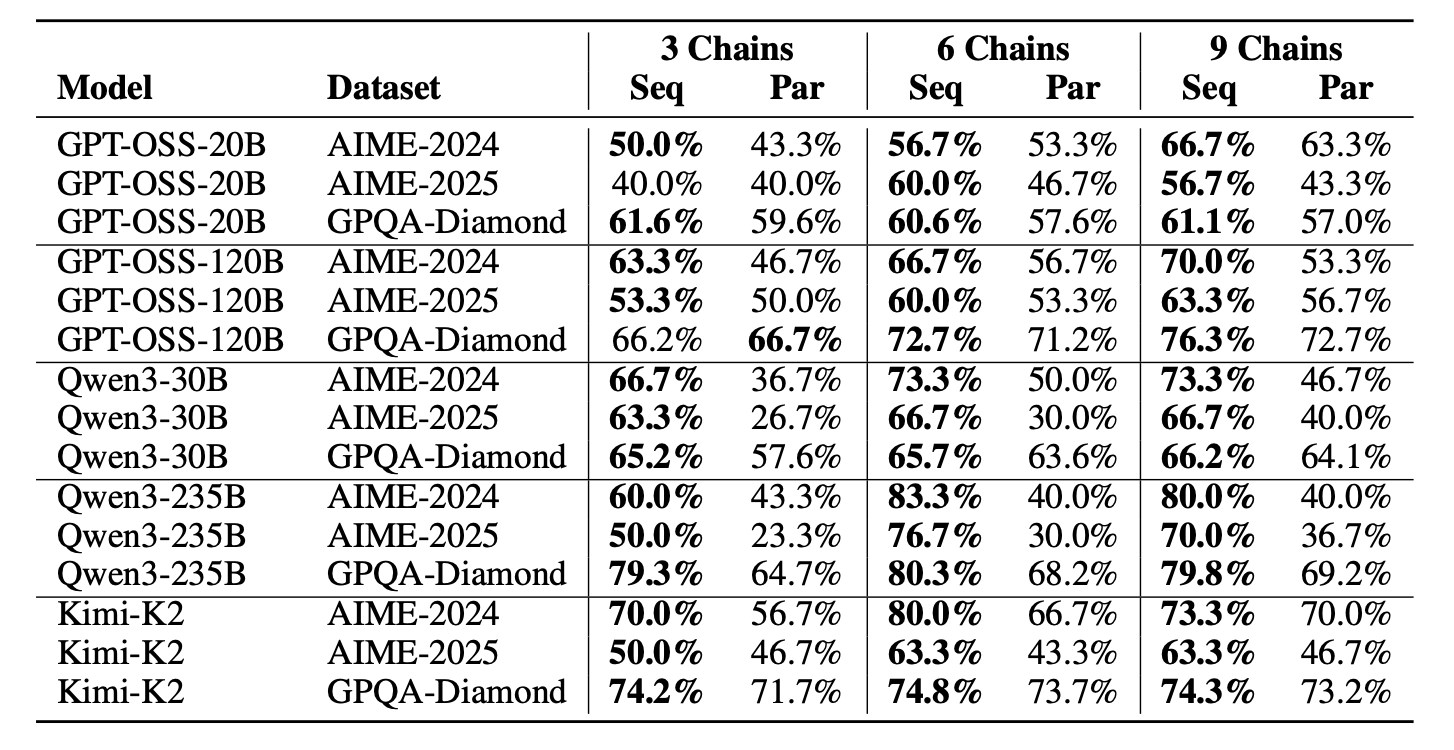
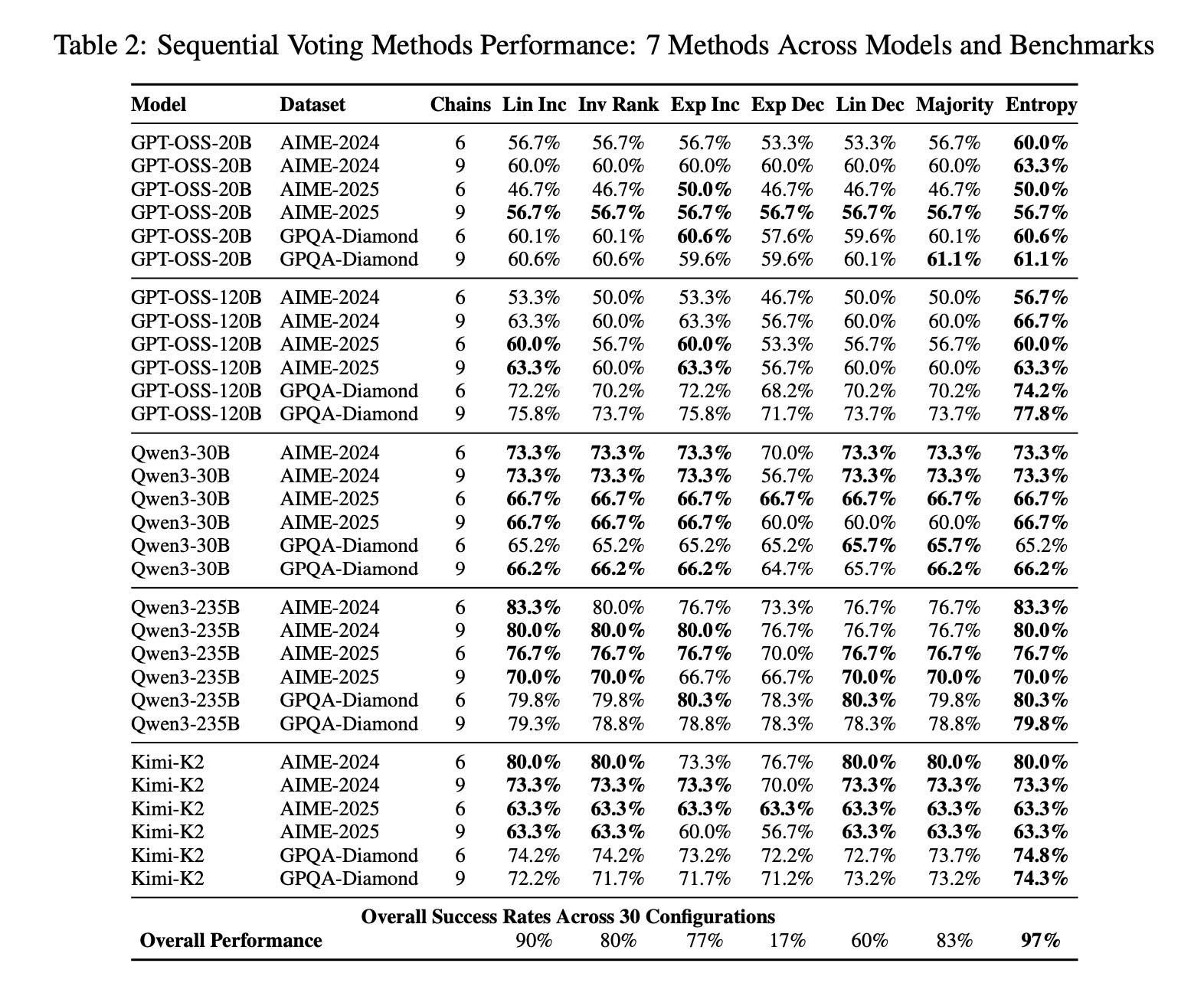
Boom: Sequential won 43 out of 45 setups (95.6%), with accuracy spikes up to 46.7% (like Qwen3-235B on AIME-2025: 76.7% vs. parallel’s 30.0%). This wasn’t model-specific; it held from 20B to 235B params, across math and science reasoning benchmarks, signaling a core strength in iterative thinking.
The secret sauce? Mechanisms parallel scaling can’t touch:
Iterative Error Correction: Models flag and patch mistakes in real time.
Progressive Context Buildup: Insights compound, turning shallow takes into profound ones.
Answer Verification: Later steps stress-test early ideas.
Here’s the full breakdown in the table below: a comprehensive grid of accuracies for sequential and parallel methods across every model, dataset, and chain count.
Leveling Up Aggregation: Inverse-Entropy Weighted Voting
Voting isn’t one-size-fits-all. Parallel sticks to majority, but sequential opens doors to nuance. We pitted seven methods, from baselines like linear increase (boosting later steps) to exponential decay (prioritizing early ones).
Our star innovation: Inverse-Entropy Weighted (IEW) Voting. It taps Shannon entropy from the model’s token logprobs to gauge confidence: low entropy means sharp, focused predictions; high means scattered uncertainty. Weight chains inversely:
Results? IEW nailed top performance in 97% of sequential runs (29/30) and 100% of parallel (gains of 0.5-3.4%). Late-leaning methods hit 90% optimality, while early ones dragged at 17%: proof that refinement adds value step by step.
Sequential scaling helps with higher diversity for creativity too (so it’s not just reasoning boost)
In an ablation on creative tasks like joke generation, sequential methods demonstrated improved quality and diversity through iterative refinement, extending the benefits beyond strict reasoning domains. Specifically, it boosted lexical richness (type-token ratio), showcasing how iteration fosters creative evolution, unlike parallel’s static independents.
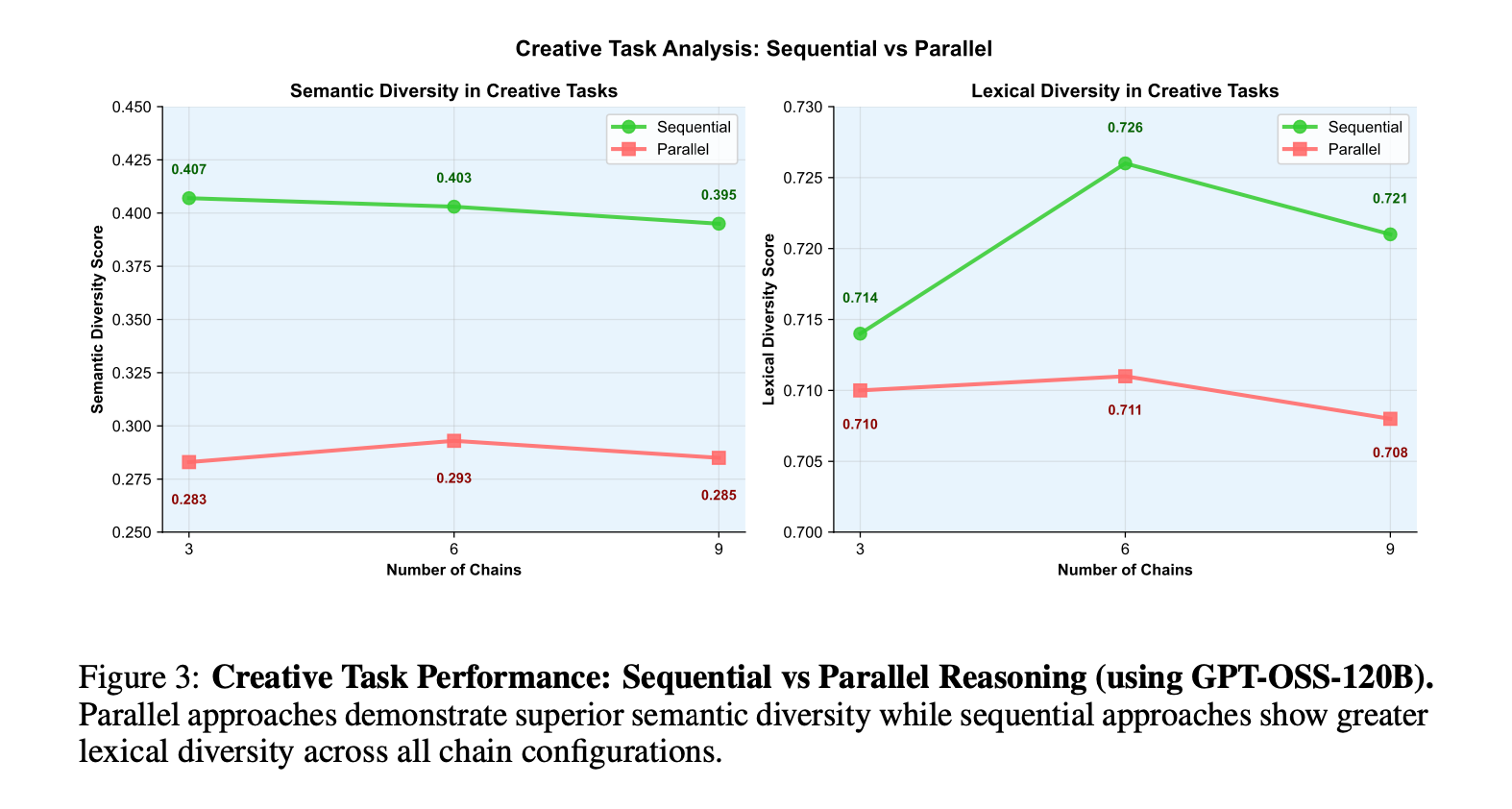
The intuition here is that if you’re asking an LLM to generate ideas, keep asking “Give me more” in the same chain instead of doing multiple parallel calls. With sequential generation, you’ll get a much higher diversity in output!
Why This Flips the Script and What’s Ahead
Since 2022, parallel has reigned supreme, but this research topples that crown. Sequential‘s built-in self-evolution positions it as the smarter go-to for optimizing inference, paving the way for more capable AI in coding, research, and countless other fields, all without inflating costs.
We’re just scratching the surface. Future work could explore hybrid approaches to further enhance performance. For the deep dive into equations, methods, and appendices, check out the full paper.
Full Paper
Read it here: The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute
Aman Sharma & Paras Chopra — Lossfunk Research
📧 aman.sharma@lossfunk.com | paras@lossfunk.com