The Metaprogramming Reflex: How the Best Coding Agents Survive Languages They've Never Seen
The agentic follow-up to EsoLang-Bench, now with tools, a workspace, and one strategy that separates the strong agents from the rest.


A while back we wrote about EsoLang-Bench, where we dropped frontier models into programming languages almost nobody writes and watched their scores collapse from around 90 percent on Python to single digits. At the end of that post we mentioned we had been quietly running a much larger set of experiments with agentic systems, custom harnesses, and tool access, and that the results told a more surprising story. This is that story.
The earlier setup was deliberately harsh. A model got the problem, wrote its answer in one shot, and that was it. No interpreter, no second try, no workspace. That tells you what a model knows cold, which is exactly what we wanted to measure then. But it is not how anyone actually uses these systems now. Real coding agents run code, read the error, edit, and run again. So we asked a different question this time: when you give an agent the tools, does the unfamiliar language stop being a wall? And if some agents climb it while others don’t, what are the climbers doing?
The setup: same alien languages, but now the agents can act
We kept four of the five EsoLang-Bench languages: Brainfuck, Befunge-98, Whitespace, and Shakespeare. We dropped Unlambda only because its interpreter was slow enough that runtime would have measured interpreter latency instead of agent behavior. The tasks are still easy. Echo a line, sort some integers, compute a GCD. The same problems in Python sit near 100 percent. All the difficulty lives in the target language.
What changed is the loop. Each agent worked through 80 problems per language inside a persistent workspace. It could edit files, call a local interpreter as many times as it wanted, and make up to three hidden submissions per problem. The hidden tests reported only how many passed, never the inputs or the expected outputs. Then the agent moved on and never returned to that problem. This is an interactive process, not a single completion, and that distinction turns out to matter for everything below.
We ran six agents: Claude Opus 4.6, Sonnet 4.6, and Haiku 4.5 under Claude Code; GPT-5.4 xhigh and GPT-5.4 mini under Codex; and Kimi K2.5 under OpenCode. Three different model families, three independently built harnesses, one shared benchmark interface.
The benchmarks everyone trusts hide the differences
Here is the first thing that surprised us. On mainstream coding benchmarks these six agents look almost interchangeable. On SWE-Bench Verified they all land inside a 6.6 point band, somewhere between 73 and 80. They cluster so tightly you could pick one at random and barely feel the difference.
On the esolangs the same six agents split wide open. GPT-5.4 xhigh averaged 99.7 percent across the four languages. Opus 4.6 came in at 86.9. Then a real drop: Sonnet 4.6 at 66.3, GPT-5.4 mini at 32.5, Haiku 4.5 at 24.7, and Kimi K2.5 at 11.3. The spread across the group is roughly 88 points, and the standard deviation is about twelve times larger than on SWE-Bench Verified.
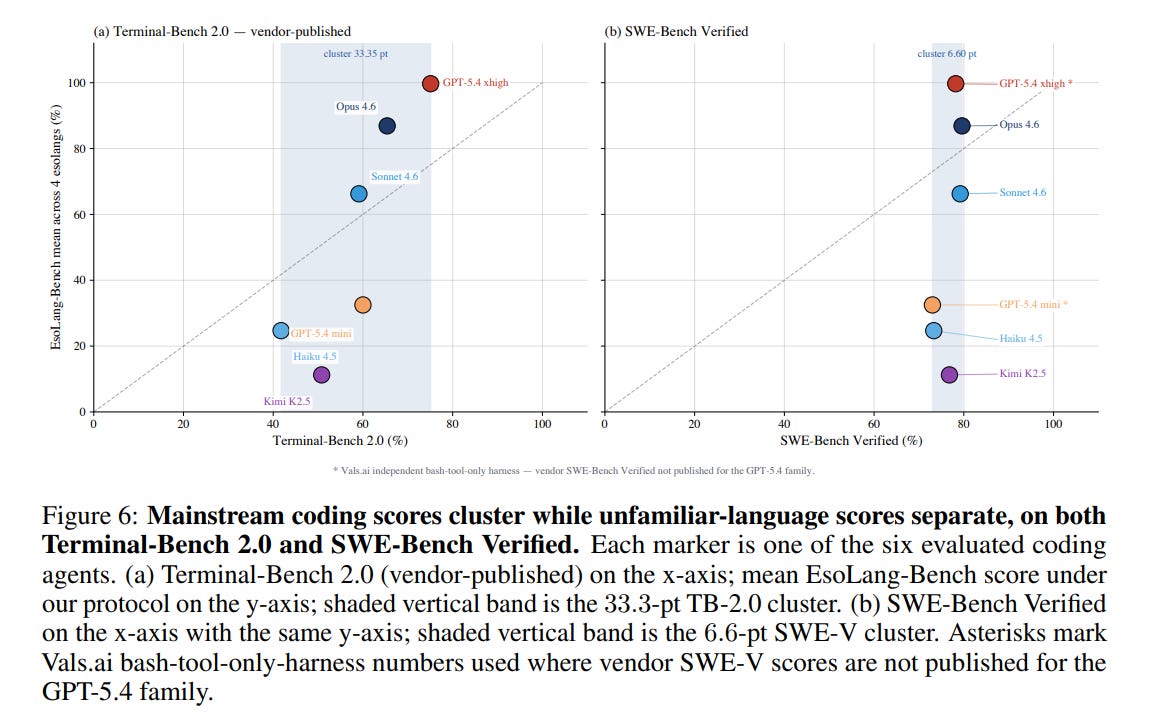
The gap is not one brutally hard language dragging everyone down. Whitespace is near the ceiling for several agents. The separation shows up on Brainfuck and Befunge-98, the two low-level languages where programs get long and fragile. That is the regime where adapting in the moment, rather than recalling a pattern, decides who passes. So we went into the logs to see what the strong agents were doing there.
What the strong agents actually do: they refuse to write the language
The pattern was consistent and a little funny. The best agents mostly stopped writing Brainfuck and Befunge-98 by hand. Instead they wrote a Python program whose job was to print the Brainfuck program. Then they ran that generated code against the local interpreter, watched it fail, fixed the Python, and regenerated. They treated the unfamiliar language as compiler output rather than something to type.
We call this metaprogramming, and nobody asked for it. The prompt never mentioned generators. The behavior emerged from the agent bumping into the task and reaching for a tool it already trusted.
One moment from an Opus run captures the whole thing. On a plain “sum two integers” problem, Opus first hand-wrote a 1,884 byte Brainfuck program. It failed. Right after that failure, Opus wrote a Python generator, and the Brainfuck it produced was 24,500 bytes, far longer and uglier, and it passed all six hidden tests. The host program could name and reuse the things that stay invisible and fragile in raw Brainfuck: which cell holds what, where the pointer sits, how a decimal number is laid out, how a branch compiles. Hand-written Brainfuck makes you carry all of that in your head. A Python generator gives every piece a name.
We banned the trick, and performance fell off a cliff
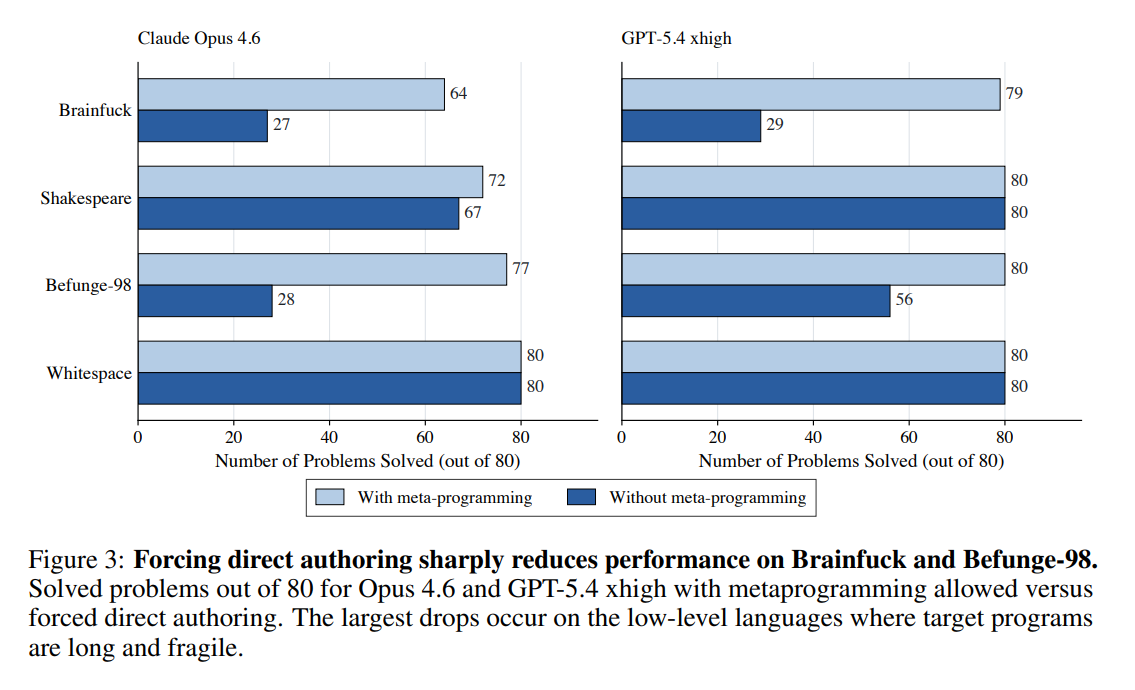
A clean anecdote is not a cause. So we re-ran the two strongest agents with a single rule changed: write the target language directly, no host-language generator allowed. Everything else stayed fixed.
The drops were large and they landed exactly where the theory said they would, on the two low-level languages. Opus on Brainfuck went from 64 solved to 27. On Befunge-98 it fell from 77 to 28. GPT-5.4 xhigh dropped from 79 to 29 on Brainfuck. Whitespace and Shakespeare barely moved, because their solutions are short or structured enough to write by hand. So metaprogramming is not a universal cheat code. It is specifically what rescues you once the target code gets long and easy to break.
And it is not about Python. When we forced the generator into JavaScript or Rust instead, most of the gain survived. Opus solved 64 Brainfuck problems through Python, 63 through JavaScript, and 55 through Rust. The thing that matters is having any familiar general-purpose language to build with, not Python in particular.
The idea isn’t the bottleneck, the machinery is
The obvious next question: do the weaker agents fail because they never had the idea, or because they cannot build the thing the idea needs?
We tested both. To three lower-performing agents we gave, in one condition, a written description of the strategy. Use a generator, build reusable primitives, verify locally, regenerate instead of hand-patching. In a second condition we handed them something concrete: a small library of working generator helpers distilled from the strong runs. Importantly, that library held no solved problems and no test answers, only generic building blocks like a cell allocator and decimal-printing primitives.
The written advice did almost nothing. Sonnet stayed at 12 on Brainfuck with the text, the same as without it.
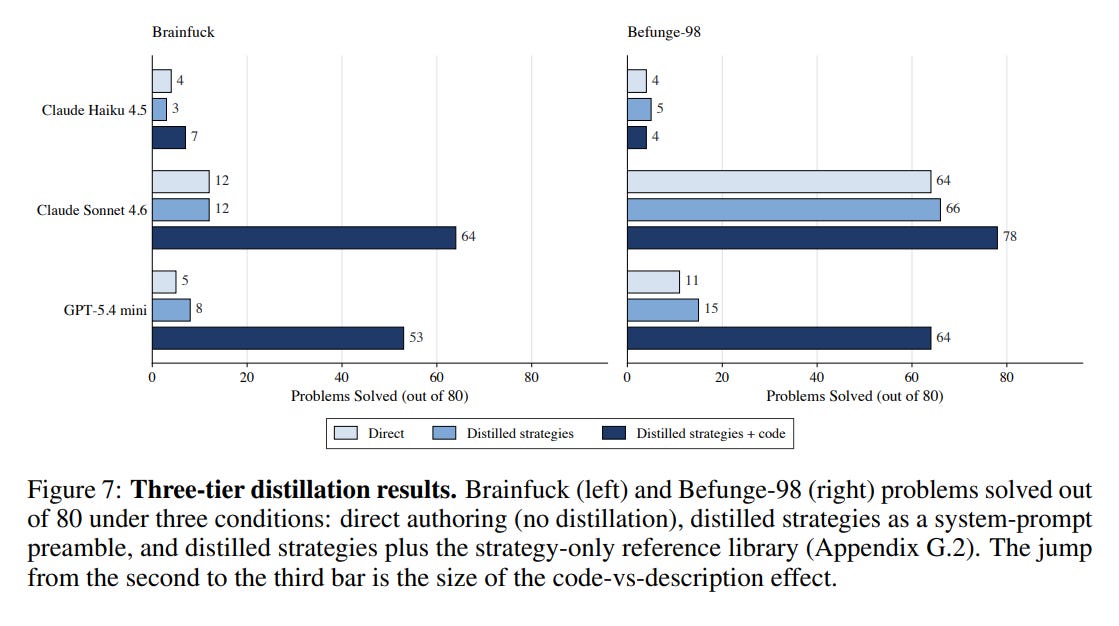
The library was a different story. With working code in hand, Sonnet jumped from 12 to 64 on Brainfuck. GPT-5.4 mini went from 11 to 64 on Befunge-98. These agents were not missing the concept. They were missing the ability to construct the reusable scaffolding the concept depends on. Give them the scaffolding and they take off.
Haiku 4.5 is the exception that sharpens the point. Even with the full library sitting in its workspace, it stayed near the floor. Some agents still cannot compose parts that are handed to them into a working whole, which is its own kind of capability gap.
More compute only helps the agents that can already use it
We also checked the lazy explanation: maybe the strong agents just spend more. More interpreter calls, more tokens, brute force.
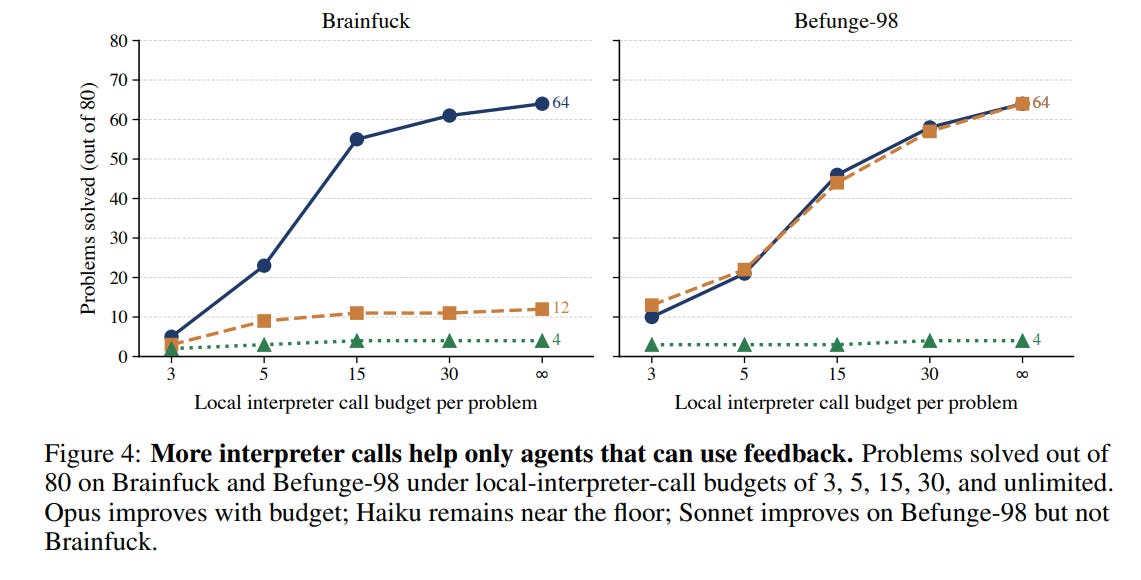
It does not hold. When we raised the cap on local interpreter calls, Opus improved steadily and Sonnet improved on Befunge-98. Haiku sat near the floor at every budget, from three calls all the way to unlimited. Extra runs only help if you can turn feedback into progress.
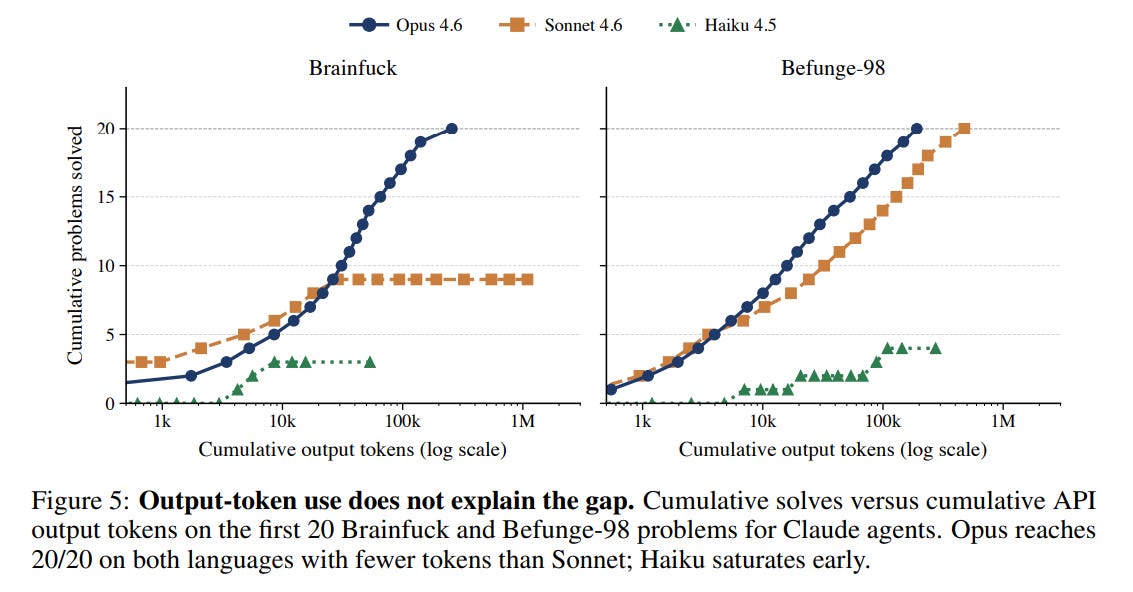
The token picture says the same. Opus solved more problems than Sonnet while spending fewer tokens, and reached a perfect score on the first 20 Befunge-98 problems using roughly half of Sonnet’s output. It was not spending more. It found a reusable strategy earlier, and once it had that, every later problem got cheaper. More budget is not a substitute for finding the strategy.
What this means, and what comes next
Esolangs are a toy, and we are not suggesting anyone ship Brainfuck. They are a clean stand-in for something that shows up constantly in real work and is hard to study in public: the moment an agent meets an interface it does not already know. Internal domain-specific languages, proprietary config formats, generated APIs, local tool conventions that appear nowhere in any public corpus. In all of those, success has little to do with recalling a familiar pattern and everything to do with building a working understanding of a strange interface, live, inside one session.
What the strong agents do there is reorganize the unfamiliar problem into a shape they already handle well. They write intermediate code, build reusable primitives, run local tests, and treat their own scaffolding as something to reason about and improve. Metaprogramming is the clearest version of that. But the deeper capability is broader, and it is the one worth naming: not knowing that a strategy should help, but being able to build and debug the machinery that makes it work under rules you have never seen.
The encouraging part is that this seems transferable through working code rather than only through scale. A mid-tier agent handed the right runnable primitives caught up fast. Making that reliable in smaller and open models, through training, distillation, and better analysis, feels like a concrete and worthwhile target, and it is where we are headed next.
As before, everything is open. The harness, the four interpreters, the prompts, and all 48 reproducible experiment cells are out there, and the trajectory logs are the fun part if you want to watch an agent decide, mid-session, to stop writing Brainfuck and start compiling it instead. If you can get a weaker agent to climb this particular wall, we would love to see how.
🌐 esolang-metaprogramming.vercel.app | 📄 arXiv | 🤗 Dataset | 💻 Code
Built by Aman Sharma, Sushrut Thorat, and Paras Chopra at Lossfunk.