The Reasoning Illusion: Why LLMs Fail When the Training Data Runs Out
EsoLang-Bench — accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026

There is a question nobody has answered cleanly about modern AI: when a model solves a hard programming problem, is it actually reasoning, or is it just remembering?
Standard benchmarks make it nearly impossible to tell. A model trained on billions of lines of Python that scores 90% on HumanEval might be doing something genuinely intelligent, or it might be doing something much simpler: pattern-matching against memorized solutions it has effectively seen before. We wanted to find out which one it actually is.
The intuition behind the work is simple. When you learn Fibonacci in Python, you can write it in Java tomorrow without years of Java training, because you transfer the logic rather than the syntax. The loop, the state, the termination condition all carry over. Syntax is just a costume, and a programmer fluent in one language can learn another in days by reasoning from first principles. LLMs claim to do something like this too, and we wanted to see whether they actually can or whether what looks like reasoning is really just a very large lookup table.
The setup: esoteric programming languages
To separate genuine reasoning from memorization, you need a setting where the model cannot fall back on anything it has seen before. That setting, it turns out, already exists. It just takes the form of programming languages almost nobody uses.
Esoteric languages are real, Turing-complete languages, capable of expressing any computation, but deliberately designed to be bizarre. Brainfuck operates with only eight commands on a 30,000-cell memory tape, with no variables, no functions, and no named abstractions whatsoever. Befunge-98 has a two-dimensional grid where the instruction pointer travels in four cardinal directions, and programs can modify themselves as they run. Whitespace encodes everything in invisible characters, where only spaces, tabs, and newlines carry meaning and all other characters are ignored. Unlambda is purely functional with no variables, relying entirely on combinators to express computation. Shakespeare writes programs as theatrical plays, where character introductions are variable declarations and dialogue performs arithmetic.
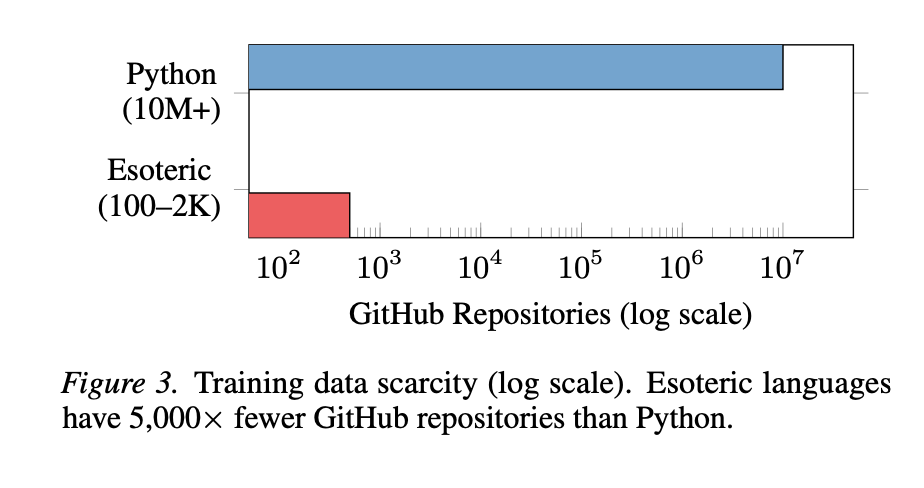
These languages all share one crucial property: they appear almost nowhere in training data. Python has over ten million public GitHub repositories, while esoteric languages have somewhere between a hundred and two thousand each. That is a gap of three to five orders of magnitude, and no rational actor would close it, since there is no deployment value in Brainfuck pretraining data and including it would likely hurt performance on mainstream languages that actually matter commercially.
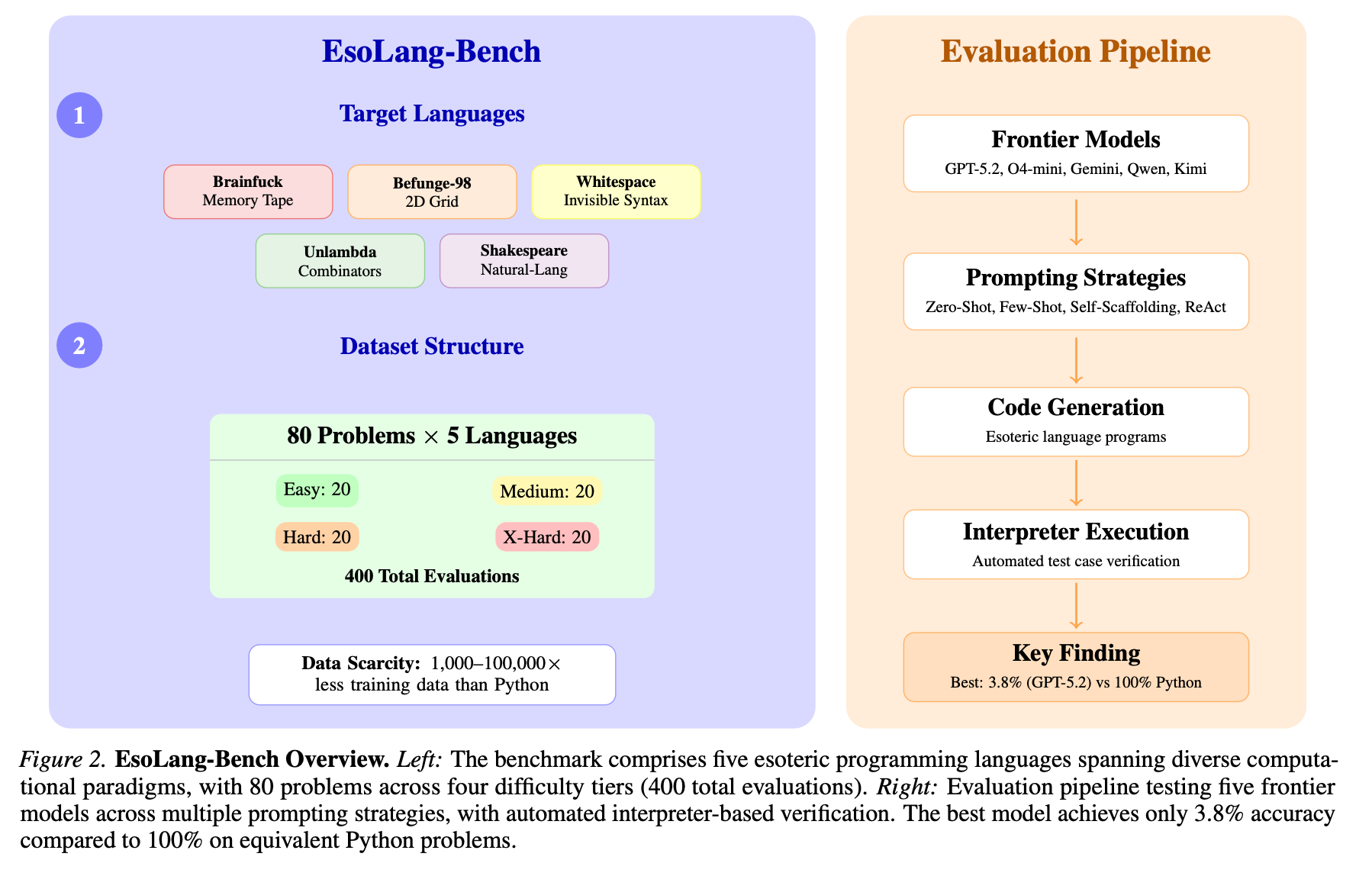
We built EsoLang-Bench around 80 programming problems across four difficulty tiers, evaluated across all five languages for a total of 400 evaluations per prompting strategy. Easy problems ask for things like summing two integers or reversing a string. Medium requires multi-step control flow like Fibonacci or factorial. Hard requires nested data structures and non-trivial algorithms like balanced parentheses or prime counting. Extra-Hard requires classical algorithms with complex state management, like the longest increasing subsequence or the Josephus problem. Crucially, the same problems appear in every language, and all evaluation is automated by running the model’s code through interpreters and checking output character-for-character.
The results were not close
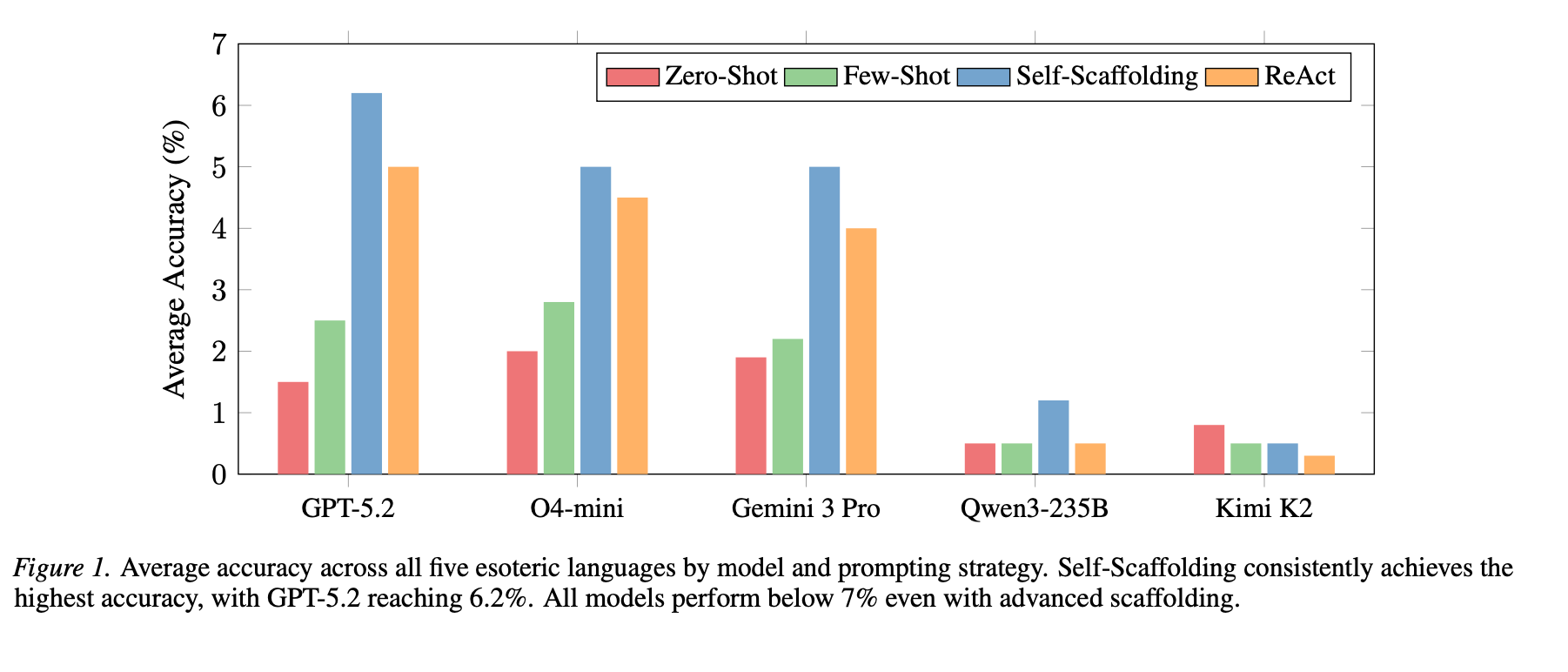
We tested GPT-5.2, O4-mini, Gemini 3 Pro, Qwen3-235B, and Kimi K2 across five prompting strategies, with three independent runs per configuration to ensure statistical reliability. These are models that score between 85 and 95 percent on HumanEval, MBPP. On our benchmark, the best model in the best configuration scored 11.2 percent, and most scored below 5 percent on average across all five languages.
More striking than the low overall numbers was what happened as problems got harder: every single model, in every language, in every prompting strategy, scored exactly 0 percent on every problem beyond the Easy tier. Not 2 percent, not 5 percent, but a uniform, absolute zero across Medium, Hard, and Extra-Hard problems for all five frontier models.
Performance also tracks data coverage with almost unsettling precision. Befunge-98, which has more online presence than the other esoteric languages, consistently produces the highest scores across all models. Whitespace and Unlambda, which have almost no public code at all, yield near-zero results everywhere. The correlation between training data availability and benchmark performance is not merely suggestive here; it is clean enough to be a near-perfect predictor.
Syntax without semantics
The error profiles add an important layer to this story. For Brainfuck and Befunge-98, where some training data exists, compile error rates are relatively low at 15 to 20 percent, but logic error rates are high at 55 to 65 percent. The model has absorbed enough surface-level knowledge to write code that runs, but it does not actually understand what the language is computing, so it produces programs that execute and produce the wrong answer. For Whitespace and Unlambda, where essentially no training data exists, 90 to 100 percent of attempts fail to compile entirely, meaning models cannot even generate syntactically valid programs from scratch.
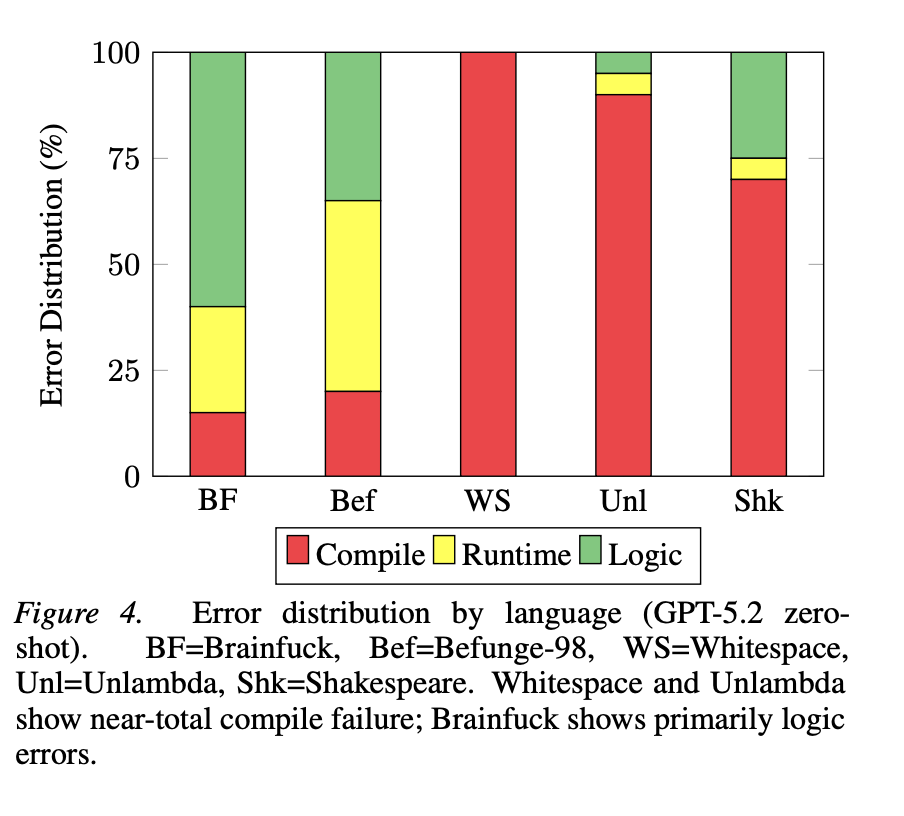
This binary pattern maps almost perfectly onto whether any pretraining coverage exists. Below some data threshold, the model has no meaningful representation of the language at all. Above it, the model has surface syntax but not the deeper computational understanding required to actually solve problems. It is the difference between knowing how a sentence is structured and understanding what it means.
We tried everything to close the gap
Before accepting these results, we spent a significant amount of effort trying to make the models work better. We tried few-shot examples, self-reflection loops, ReAct pipelines with separate coder and critic roles, and iterative interpreter feedback across up to five refinement rounds per problem.
Few-shot prompting improved accuracy by an average of 0.8 percentage points across all configurations, which is not statistically significant at any reasonable threshold (Wilcoxon p = 0.505). The reason, we think, is fairly fundamental to how in-context learning actually works: demonstrations activate knowledge that already exists from pretraining rather than teaching genuinely new skills. When the target domain lies outside the pretraining corpus, a few examples in the context window cannot compensate for absent foundational knowledge. You cannot retrieve what was never stored.
Self-scaffolding, where a single model receives direct interpreter feedback and refines its solution across up to five iterations, was the most effective non-agentic strategy. Interestingly, it matched or outperformed the two-model coder-critic setup while using half the compute. The reason seems to be that on out-of-distribution tasks, concrete execution traces provide a sharper learning signal than another model’s textual interpretation of what went wrong. When the critic is also ignorant of the target language, it introduces noise rather than signal, and the raw feedback from the interpreter turns out to be more useful.
What this means, and what comes next
The hard performance cliff we observed, where every model scores zero on everything beyond the Easy tier across all five languages and all prompting strategies, suggests this is not an incremental gap that more compute or better prompting will gradually close. Easy problems require mapping simple single-loop patterns to novel syntax, which is at least partially achievable by retrieving fragments of sparse training data. Medium problems and above require multi-step algorithmic reasoning that must be constructed from scratch in an unfamiliar domain, and no current frontier model can do that reliably.
We have been quietly running a much more extensive set of experiments with agentic systems, custom evaluation harnesses, and tool-augmented setups that we think tell a genuinely surprising story about where the ceiling actually is and what it would take to push past it. That work is coming soon, and we think the results will be worth the wait.
In the meantime, we would love for the broader community to engage with this benchmark directly. The dataset, interpreters, and evaluation code are all open-source, and we are genuinely curious whether anyone can find a prompting strategy, a fine-tuning approach, or an inference-time trick that meaningfully moves the needle on the Medium tier and above. If you think you can get a model to solve most of these problems, please try it and share what you find.
More broadly, we hope this work is a small argument for a different kind of benchmark culture. The field has gotten very good at building static benchmarks that measure what models have memorized, and models have gotten very good at being trained on those benchmarks until the numbers look impressive. What we need more of are benchmarks designed around transferable, human-like reasoning: evaluations where gaming is economically irrational, where the only path to a high score is genuine generalization, and where high performance actually tells you something meaningful about what the model can do. We would love to see more work in this direction, and we hope EsoLang-Bench is a useful template for what that can look like.

🌐 esolang-bench.vercel.app | 📄 arXiv | 🤗 Dataset | 💻 Code
Built by Aman Sharma and Paras Chopra at Lossfunk.
Super interesting post!