What is research and how to do it?
or, can you teach an AI how to do good research?

Recently at Lossfunk, we hosted Shashwat Goel for a talk on how he conducts research. It was fascinating and perspective-shifting. We will release the video soon, but till then, here's my notes on how to think about research based on what Shashwat talked about and then I modified and extended it with my own perspective.
At Lossfunk, one of our core projects is to see how do we use AI to accelerate AI research itself. For that, the question transforms to "what actually is research?"
Previously, I wrote a manifesto on how to do good science in AI (something we’re trying to follow in our lab).
Manifesto for doing good science in AI

Good science is about discovering knowledge that’s:
a) Novel: i.e. it that hasn’t been explored before
b) Impactful: i.e. once discovered and communicated, it guides future efforts of a community for years to come
Now, I’m attempting something more ambitious - if you were to think of the search as an algorithm, what would that algorithm look like?
(I am aware of Feyerabend’s Against Method, and I subscribe to it. So what I mention here is simply one way of approaching research. I’m not claiming it is the ONLY way).
What is research?
Research literally is about reducing uncertainty in humanity's knowledge about the world.
Frontier knowledge of humanity is manifested as knowledge that a specific scientific community possesses.
So research practically amounts to reducing uncertainties within a community.
Your job as a researcher should be to help answer more uncertainties that a specific community still doesn't have full clarity on.
What kind of uncertainties matter and how to find them?
Uncertainties come in various shapes and forms. Some are trivial, like "What color t-shirt will my friend wear tomorrow?" while others are major, like "What happened the other day, man?"
From another perspective, you have personal uncertainties - things that you don't know about. When you uncover them, that's just learning. And then you have uncertainties in a community where nobody really knows the right answer, and uncovering them is called research.
In my experience, a lot of uncertainties are mostly personal uncertainties - where someone somewhere out there knows the answer, but you don't. In that case, finding out whether the uncertainty you have is an actual uncertainty in a community or it's a personal uncertainty is a good first step. Doing a literature review and background survey is essential, and perhaps that's why it should be the first step of research.
To find uncertainties in a particular field, it might be a good idea to create a tree-like structure where:
You start with a subfield or question
You branch it off to more and more aspects
You map what uncertainties exist at each node level
An example of this is the following graphic:
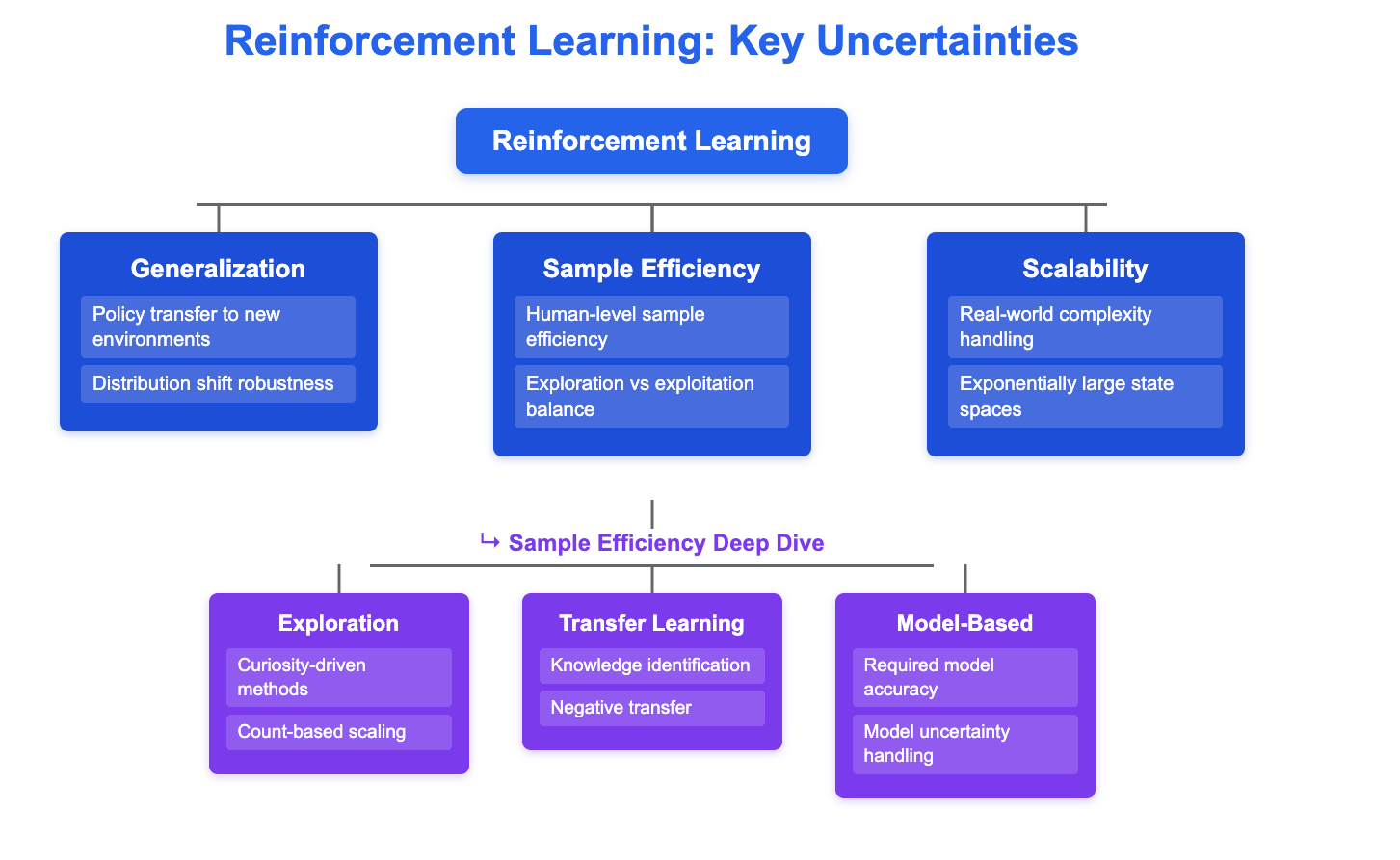
How to prioritize which uncertainties to focus in your research?
Since realistically you will be spending a significant time on research, it makes sense to prioritize what uncertainty do you want to spend time answering or resolving.
I think a good prioritization framework incorporates following three factors:
Impact as measured by how many future projects will use or refer to your work
Neglectedness. If counterfactually others will resolve that uncertainty soon, your effort isn't important so it makes sense to ask what won't happen if you don't do it
Tractability. With the resources you have, can you realistically win to make progress?
To apply this prioritization framework, you need to know a list of all the uncertainties downstream of a question that you are interested in. So it makes sense to make a tree-like decomposition starting with your root question.
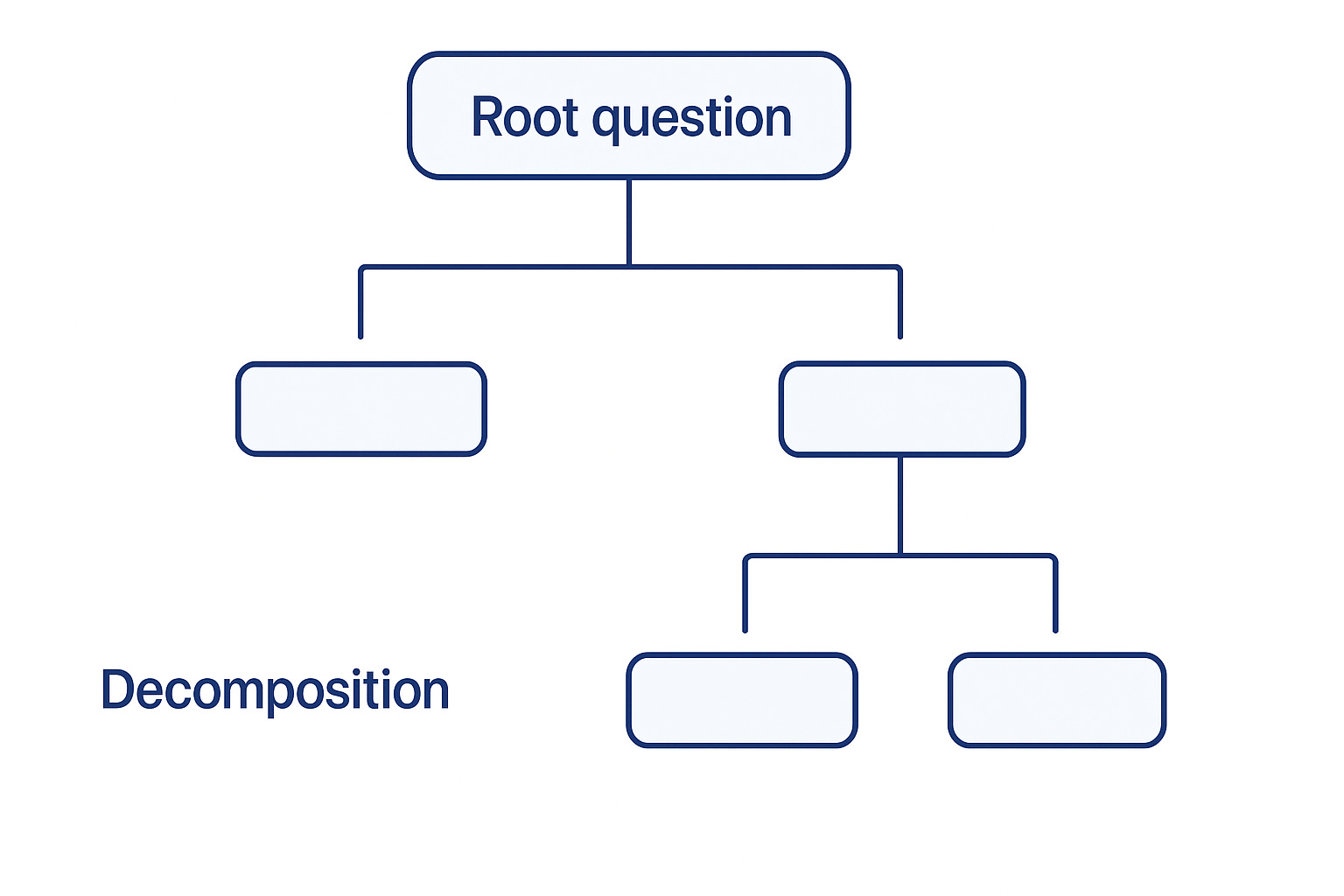
This tree is a living process. Before you jump to selecting a research question from this tree, it might be important for you to read the literature widely and refine your understanding. Read review papers and talk to experts. Consider having a sort of like a reconnaissance phase before prioritization.
Once you have a decomposition of your question / problem of interest that you’re satisfied with, you need to start filling the nodes.
What to fill in each node:
Write foundational assumptions and key results in each node, and what uncertainties still unresolved.
Once you have nodes filled in, rank uncertainties by impact, neglectedness, and tractability to shortlist questions/uncertainties you want to focus on during the next 6-9 months.
How to go from selected uncertainties to experiments?
The uncertainty you select is sort of like a problem you are attaching yourself to. It's much better to align with the problem instead of an idea or a solution because ideas can come and go, but problems are more everlasting. Since you'll be spending 6-9 months on your research project, being obsessed about a problem is a better idea than being obsessed about an idea which may or may not work out.
Once you have a selected uncertainty, you can phrase it as your research question. The next step is pretty simple:
From research question, you select hypothesis
From hypothesis, you select experiments
I detailed this research question → hypothesis → experiments process in my previous article.
How to prioritize which experiments to run?
As soon as you have narrowed down to your research question and have initial hypotheses and experiments, do some quick and dirty validation to build a better intution, and also reach out to community members for their feedback. They can ultimately also become co-authors.
When you want to prioritize which experiments to run once your research project begins, prioritize experiments that maximize learning (or resolve most amount of uncertainty). If you like, you can call it the minimal viable experiments.
Don't do the easiest experiments first. That's a temptation, but they teach you probably the least. You want to fail early if some of your experiments don't yield insights that you were looking for.
When to end your research project?
Research is endless, and ending your research is one of the toughest decisions to make because there's always something more to do. A practical tip:
Stop your research project when you have one key message that you can make evidence-based claims on.
This key message becomes the meat of your paper that you write.
Of course, paper writing is a skill in itself, and it's a topic for a future post. But in short, make sure you do enough ablations and do comparisons with baselines. And of course, you need to market your research by marketing your paper. If you do want to read more on how to write a good paper, I like this blog post.
Anticipating more of your questions
What about my research ideas? I have tons of them
Getting excited about ideas is okay, but know that the choice of problem will have far more impact than a particular solution or an idea. So, be focused on a problem like "how to make LLMs better at reasoning" while being open towards different solutions.
What about trying to beat SOTA? Everyone talks about SOTA in AI
Trying to get to SOTA is an engineering project, not a research problem, so chasing SOTA may not be a good idea. Even if you get SOTA, you'll get surpassed again soon. Even if you get SOTA on a particular benchmark, your method may not generalize.
What about novelty? Does all research need to be novel?
Yes, novelty should be there in the sense of trying to answer an uncertainty that nobody really knows an answer about. But the novelty should not be necessarily in the method itself.
Uncertainty reduction can happen by using existing methods or by simply highlighting a new problem that the community has overlooked. For example, could you take existing methods of benchmarking and embedding models and benchmark them in a new field that nobody has done before? So is it novel? Yes, nobody has done this before. But is it a novel method? No, people have done this in different fields.
Levels of research uncertainties
Well, thinking about what kind of uncertainties exist, I went to the rabbit hole of trying to systemize them into multiple levels. Here's what I came up with:
Known uncertainties - uncertainties about answers. these are what the community knows exist but we don’t have answers for
Foundational assumptions - uncertainties about questions/assumptions in a field. these uncertainties emerge out of questioning the foundational assumptions and result in a field.
Conceptual blind spots - uncertainties about what’s conceivable (beyond the current framework). these are uncertainties that exist but cannot be articulated within a field’s current paradigm
Domain boundaries - uncertainties about what constitutes a domain/boundary of a field of enquiry
Examples of the four levels of research uncertainties
Level 1 - Known uncertainties
How to achieve sample-efficient RL?
How to make LLMs more interpretable?
How to prevent catastrophic forgetting in continual learning?
Level 2 - Foundation assumptions
Is the scaling hypothesis correct? Under what circumstances does it fail? (This questions the basic assumption that "bigger models = better models")
Can we formulate a different objective function for language models other than auto-regressor next to completion? (This questions the dominant current pardigm of training models)
Should we optimize for reward maximization at all? (This questions the basic assumption of RL.)
Level 3 - Conceptual blind spots
Relationship between consciousness and intelligence. (Current ML theory is completely mechanistic)
Non-computational forms of intelligence. (We lack vocabulary for it)
Collective intelligence. What does the word 'collective' here even mean?
Level 4 - domain boundaries
AI-Human co-evolution studies:
Computational phenomenology: what it feels like to be in an AI
As you can see, the higher the level you go, the more impactful your research is going to be, but the less feasible that research could be because the uncertainty is going to just balloon up.
My sense is that one should look for the highest level you can make concrete progress on.
TLDR: Closing with a practical tip
I know that systematically mapping a whole subfield for weeks is often intractable, but when you get excited by an idea, it might be worth spending 30 minutes on answering following for your ideas:
Defining what certainty are you actually reducing here?
Has it been done before? Is it your personal uncertainty or a shared one?
Is it important and tractable?
The author, Paras Chopra, is founder and researcher at Lossfunk.
Thanks for writing this article, It is super helpful. I found.. Mapping the personal uncertainty to larger group of people around you is difficult. We need more good mechanism to bring people together who shared uncertainty.
Thank you for sharing the framework. Helps looking at these problems from a new lens.