Why LLMs Aren't Scientists Yet
Case study from four attempts at autonomous research and getting an AI-written paper published at an experimental conference.

As a part of our explorations in AI for Science, we set out to answer how far can current SoTA reasoning LLMs go in doing autonomous research with minimum scaffolding. Could they go from a high level research idea to a complete paper?
To answer this, we built a six-agent pipeline using Gemini 2.5 Pro and Claude Code, and tested it on four research ideas across World Models, Multi-Agent RL, and AI Safety. Three failed. One succeeded and got accepted at Agents4Science 2025, the first academic conference requiring AI as primary author.
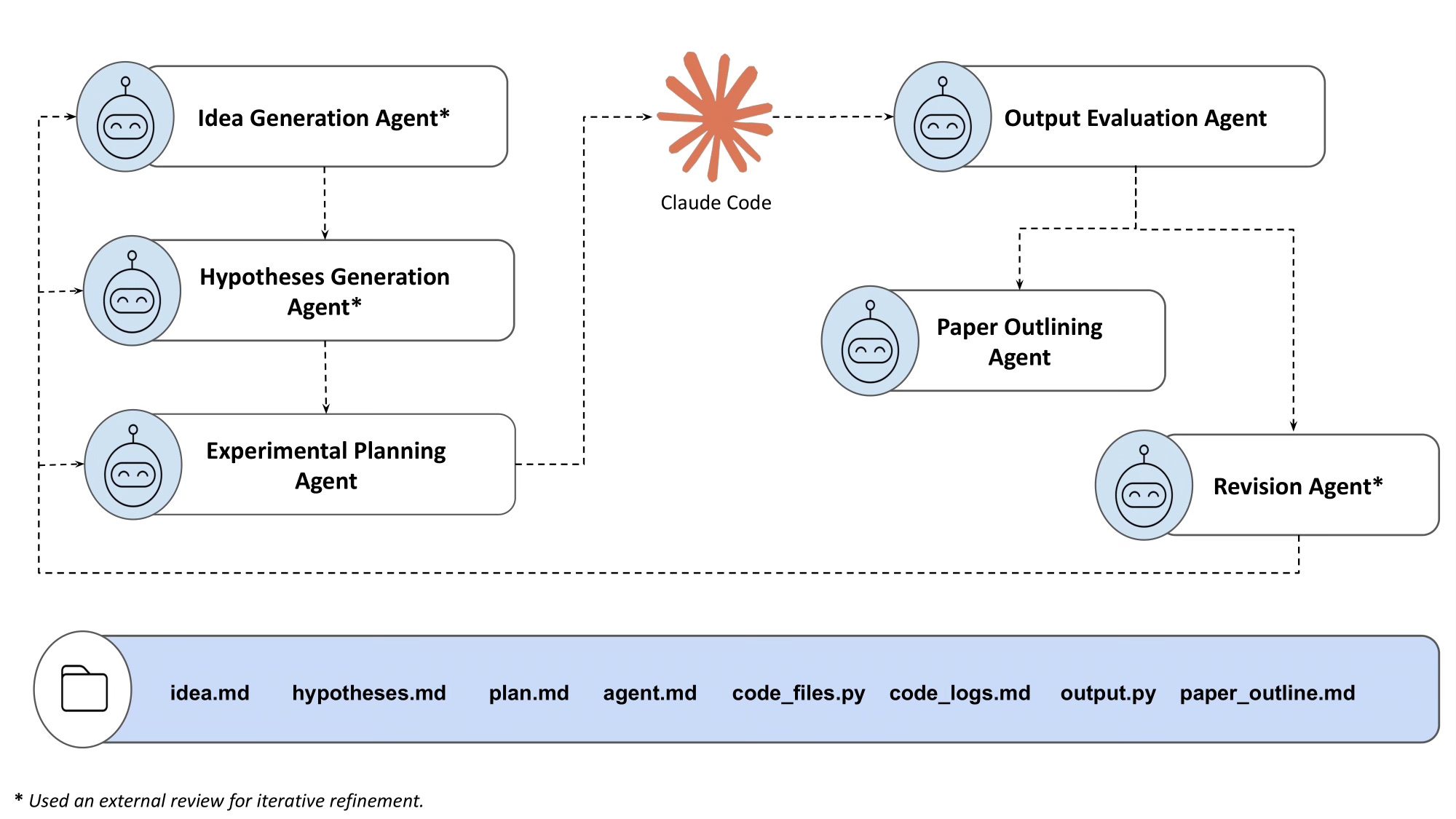
Along the way, we observed six recurring failure modes and realised four design principles for designing robust LLM Scientist systems. We release a technical report on arXiv (arxiv.org/abs/2601.03315) and corresponding website (whyaiscientistsfail.lossfunk.com) detailing these, our system architecture, each research attempt, and broader implications for LLMs in Science.

You can also go through the highlights on our X thread below.


This is early work with clear limitations. We ran only four ideas, in three ML subdomains, no systematic ablations, and identify failure modes through observation rather than quantitative measurement. But we see it as a starting point for understanding where LLM scientists break and how to build better ones. If you’re working on similar problems or have thoughts, we’d love to hear from you.
Dhruv Trehan & Paras Chopra — Lossfunk Research
📧 dhruv.trehan@lossfunk.com | paras@lossfunk.com
Try Gemini 3 pro and opus 4.5
I'm sorry but this post in itself doesn't contain any useful information outside of just linking to other reports and the X thread . The title and initial sentences makes it seem like there's actual content/takeaways to follow.